Edge AI is the practice of running machine learning inference directly on local devices such as phones, sensors, cameras, wearables, embedded boards, industrial controllers, and other endpoint hardware rather than relying entirely on remote cloud infrastructure. It enables low-latency, privacy-aware, bandwidth-efficient, and resilient intelligent behavior close to where data is produced. This whitepaper explains the technical foundations of Edge AI and focuses on deploying models with TensorFlow Lite.
Abstract
As machine learning expands into mobile, IoT, automotive, healthcare, retail, robotics, and industrial environments, inference increasingly needs to happen on-device rather than only in centralized data centers. Edge deployment changes the engineering problem substantially: models must fit within limited memory, compute, storage, power, and thermal budgets while still meeting accuracy and latency requirements. This paper explains edge inference architecture, on-device constraints, model optimization for deployment, quantization, pruning, delegated hardware acceleration, offline behavior, update strategies, privacy implications, and real-world device considerations. It then examines TensorFlow Lite as a major deployment framework for bringing TensorFlow-trained models to mobile and embedded environments. All formulas are embedded inline in HTML-friendly format for direct use in WordPress or similar editors.
1. Introduction
Let a trained model be represented as:
ŷ = f(x; θ),
where x is the input, θ is the trained parameter state,
and ŷ is the predicted output.
In cloud deployment, inference is typically executed on a remote server:
device → network → server inference → network → result.
In edge deployment, inference is executed directly on the device:
device inference → result.
This architectural shift changes latency, privacy, reliability, cost, and systems design trade-offs.
2. What Edge AI Means
Edge AI refers to AI computation performed at or near the data source rather than entirely in the cloud. Edge devices may include:
- smartphones
- IoT gateways
- embedded microprocessors
- cameras and smart sensors
- industrial equipment
- medical devices
- automotive systems
- retail and robotics hardware
The “edge” is therefore not one specific hardware class but a deployment location relative to data generation.
3. Why Edge AI Matters
Edge AI is important because many real-world applications need:
- low latency
- offline or intermittent-network operation
- reduced bandwidth usage
- privacy-preserving local inference
- faster response to local events
- lower dependency on cloud connectivity
In some applications, such as real-time vision or safety-critical control, cloud-only inference may be too slow or too fragile.
4. Cloud AI vs Edge AI
In cloud AI, inference benefits from large-scale compute and flexible scaling. In edge AI, inference benefits from local responsiveness and data locality.
If cloud round-trip latency is Lnet + Lcloud and on-device
inference latency is Ledge, edge deployment is advantageous when:
Ledge < Lnet + Lcloud
and other constraints are acceptable.
5. Common Edge AI Use Cases
Typical Edge AI scenarios include:
- on-device image classification
- keyword spotting and speech detection
- object detection in cameras
- predictive maintenance on industrial equipment
- gesture recognition on wearables
- offline language and translation tools
- driver assistance and automotive perception
6. Core Constraints of Edge Deployment
Edge deployment is defined by constraints that are much tighter than in the cloud. Common constraints include:
- limited memory
- limited storage
- limited CPU/GPU/NPU compute
- strict power consumption budgets
- thermal limits
- platform-specific runtime availability
- smaller operating system and library footprints
Therefore, a model that works well in a training environment may still be unsuitable for edge deployment.
7. Latency on the Edge
In many edge use cases, latency is one of the most important metrics. If inference latency is
L, application success may require:
L ≤ τ,
where τ is the maximum acceptable response time.
This threshold can be very strict for voice interaction, camera pipelines, or industrial control systems.
8. Memory Footprint
Edge devices may have tight RAM budgets. If model parameter count is
P and each parameter uses
b bytes, a simplified parameter-memory footprint is:
Memory ≈ P · b.
Activations, intermediate tensors, runtime overhead, and operator buffers add additional memory requirements beyond the parameters themselves.
9. Storage Footprint
On-device models must also fit storage constraints. Large model files increase download time, occupy device storage, and complicate update workflows. This is one reason why smaller model architectures and compressed formats are often necessary for edge deployment.
10. Power and Energy Constraints
Edge devices often operate on batteries or must stay within strict power budgets. If average power draw is
P and inference duration is t, then energy consumed per
inference can be approximated as:
E = P · t.
Reducing model complexity can therefore improve not only speed, but also battery life and thermal stability.
11. Thermal Constraints
Intensive on-device inference can raise device temperature. Sustained thermal load can lead to throttling, where the device reduces performance to avoid overheating. This means that peak benchmark results may differ from sustained real-world performance.
12. On-Device Privacy Advantages
One of the strongest arguments for Edge AI is privacy. If raw user data remains on the device and only inference results are used locally, exposure risk can be reduced compared with always transmitting raw data to the cloud.
This does not eliminate privacy risk entirely, but it reduces dependence on centralized raw-data collection.
13. Reliability and Offline Operation
Edge inference can continue even when connectivity is poor or unavailable. This is useful in:
- remote environments
- industrial sites
- vehicles
- mobile use cases with unstable networks
- emergency response contexts
Edge AI therefore improves resilience for applications that cannot always rely on cloud access.
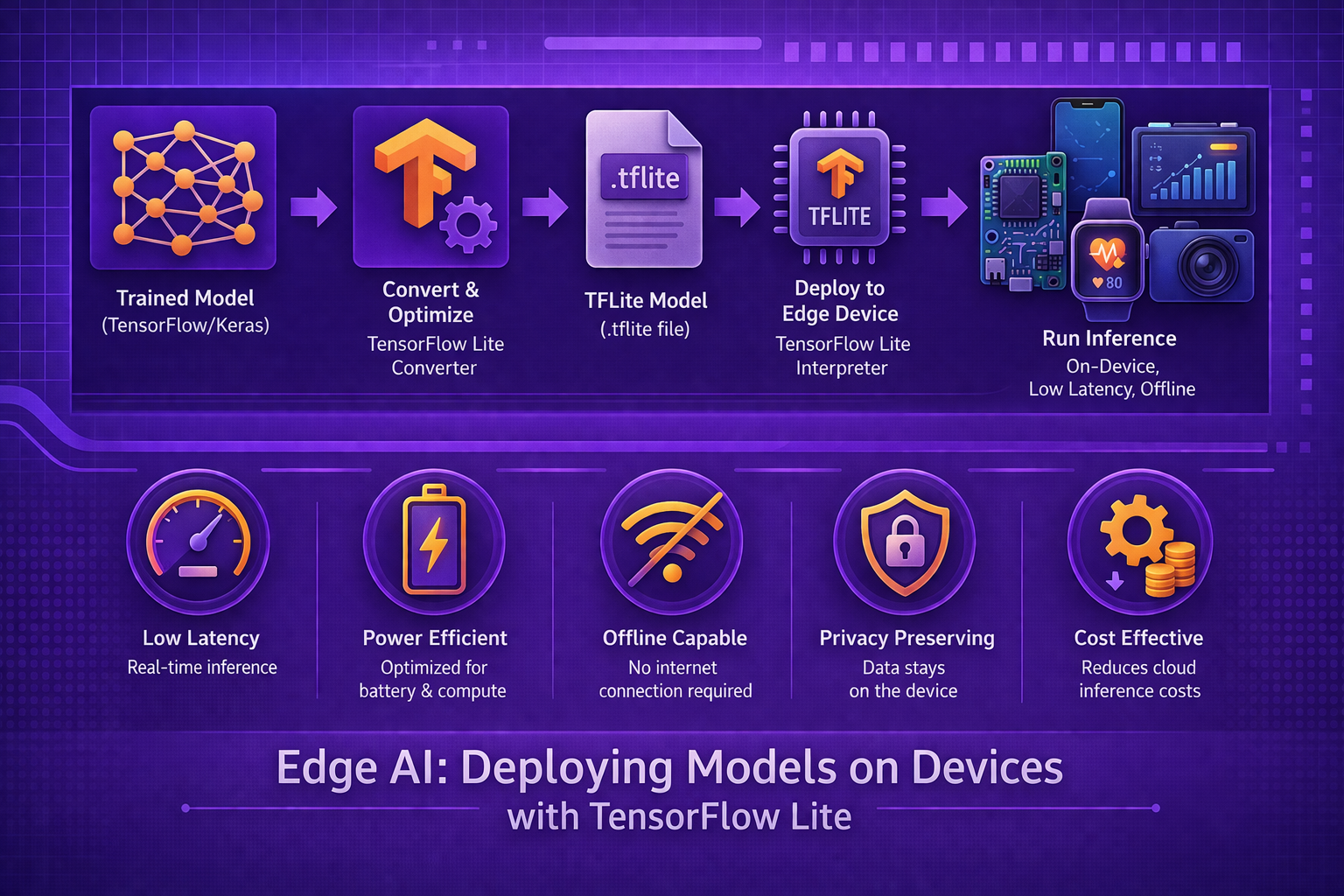
14. The Edge AI Pipeline
A typical edge deployment lifecycle looks like:
train model → optimize model → convert format → deploy to device → run inference → monitor/update.
This differs from cloud deployment because optimization for device constraints is usually much more important.
15. TensorFlow Lite Overview
TensorFlow Lite is a lightweight machine learning runtime and model format designed for on-device inference. It is intended for mobile, embedded, and edge environments where full TensorFlow may be too heavy.
TensorFlow Lite provides:
- a compact model format
- an interpreter for on-device execution
- support for optimization techniques such as quantization
- hardware acceleration through delegates
- deployment pathways for Android, iOS, and embedded systems
16. TensorFlow Lite Conversion
A TensorFlow-trained model is typically exported and converted into TensorFlow Lite format before device deployment.
Conceptually:
Mtrain → Convert → MTFLite.
The conversion stage can apply optimizations that reduce size and improve runtime performance.
17. TensorFlow Lite Interpreter
TensorFlow Lite uses an interpreter-based execution model. The interpreter loads the model, allocates tensors, binds inputs, executes operators, and reads outputs. This runtime is designed to be smaller and more deployment-friendly than full training-oriented TensorFlow stacks.
18. Quantization
Quantization is one of the most important optimization techniques for edge deployment. It reduces numerical precision to lower memory and computation cost. For example, weights stored as 32-bit floating-point values may be converted to 8-bit integers.
A simplified affine quantization relation is:
q = round(x / s) + z,
where:
xis the real-valued quantityqis the quantized integer valuesis the scalezis the zero-point
18.1 Why Quantization Helps
If a model originally stores parameters using 32 bits per weight and is quantized to 8 bits, parameter storage can shrink by approximately a factor of 4, ignoring metadata overhead. This can significantly improve:
- model size
- memory bandwidth efficiency
- inference speed on supported hardware
- energy efficiency
18.2 Trade-Offs of Quantization
Quantization may reduce numerical precision and sometimes degrade model accuracy. The deployment challenge is to find whether the accuracy loss is acceptable relative to gains in efficiency and deployability.
19. Dynamic Range, Float16, and Full Integer Quantization
TensorFlow Lite supports several quantization modes, each balancing compatibility, performance, and numerical precision differently. Common approaches include:
- dynamic range quantization
- float16 quantization
- full integer quantization
The choice depends on target hardware and accuracy tolerance.
20. Quantization-Aware Training
Rather than only quantizing after training, models can also be trained with awareness of later quantization effects. This helps the model adapt to lower-precision behavior and often improves final quantized accuracy compared with naive post-training quantization.
21. Pruning
Pruning removes less important weights or structures from a trained model. If total parameter count is
P and fraction ρ is pruned, remaining parameter count is:
P' = (1 - ρ)P.
Pruning can reduce model size and, in some deployment settings, improve efficiency, especially when paired with compression-aware runtimes.
22. Knowledge Distillation
Another common technique for Edge AI is knowledge distillation, where a smaller “student” model is trained to mimic a larger “teacher” model. The goal is to preserve much of the teacher’s behavior while producing a compact model more suitable for device deployment.
23. Hardware Acceleration and Delegates
Edge devices may expose specialized acceleration hardware such as GPUs, DSPs, or NPUs. TensorFlow Lite supports delegates that allow parts of the model graph to run on such accelerators rather than only on the CPU.
This can reduce latency and energy usage significantly when the model and device are compatible.
24. Operator Support and Compatibility
Not every operation used during model development is always available or equally optimized on every edge runtime. Therefore, model architecture design may need to consider deployment-friendly operators from the start.
A model that is mathematically valid may still be deployment-problematic if its operator set is poorly supported on target devices.
25. Input Pipelines on Devices
Edge deployment also requires efficient local preprocessing for inputs such as:
- camera frames
- audio signals
- sensor values
- text token sequences
If preprocessing cost is Lprep and model inference cost is
Linfer, total pipeline latency is approximately:
Ltotal = Lprep + Linfer + Lpost.
Thus, optimizing the model alone may be insufficient if preprocessing dominates runtime.
26. Model Updates on Devices
Deployed edge models may need updating due to:
- improved accuracy
- bug fixes
- new label sets
- security or compatibility issues
- drift adaptation
This requires versioned update mechanisms that preserve reliability and allow rollback if a new model performs badly.
27. Edge AI vs Hybrid Edge-Cloud AI
Not all applications should be fully edge-only. A hybrid pattern is often useful:
- run fast screening or local inference on-device
- escalate difficult or expensive cases to the cloud
- synchronize updates or analytics when connectivity is available
This combines the latency and privacy benefits of edge inference with the compute flexibility of cloud systems.
28. Accuracy-Efficiency Trade-Off
Edge deployment often requires trading some model fidelity for deployability. If predictive performance is
A and efficiency is E, model selection for edge devices
is often about finding an acceptable point on the trade-off surface rather than maximizing
A alone.
29. Security and Integrity on Devices
Edge deployment introduces security concerns such as:
- model extraction
- tampering with model files
- reverse engineering
- unauthorized inference misuse
- device compromise
Therefore, model packaging, secure storage, code signing, and controlled update channels are important operational protections.
30. Monitoring Edge Deployments
Monitoring Edge AI is harder than monitoring centralized cloud services because devices may be offline, diverse, and privacy-constrained. Useful monitoring signals may include:
- latency summaries
- failure counts
- hardware delegate usage
- resource and battery impact
- model version adoption
- privacy-safe aggregated prediction diagnostics
31. Typical Strengths of TensorFlow Lite
- compact deployment-oriented runtime
- strong integration with TensorFlow models
- support for quantization and optimization
- mobile and embedded deployment pathways
- hardware acceleration support through delegates
32. Typical Limitations of TensorFlow Lite
- operator support constraints compared with full training environments
- deployment tuning still depends heavily on target hardware
- not every model architecture converts cleanly or efficiently
- edge optimization often requires iterative benchmarking rather than one-click conversion
33. Common Failure Modes
- deploying a model that is too large for memory constraints
- quantizing aggressively without checking accuracy degradation
- ignoring preprocessing cost and optimizing only the core model
- assuming benchmark latency equals sustained on-device latency
- neglecting battery and thermal effects
- shipping models without secure update and rollback mechanisms
34. Best Practices
- Design with deployment constraints in mind from the beginning, not only after training.
- Benchmark on real target devices rather than relying only on desktop or simulator results.
- Use TensorFlow Lite conversion and quantization strategically, with accuracy validation after each optimization.
- Measure end-to-end latency, including preprocessing and postprocessing, not just model invocation time.
- Consider hybrid edge-cloud architectures when full local inference is not ideal.
- Plan for secure model updates, monitoring, and rollback on deployed devices.
35. Conclusion
Edge AI is a foundational deployment paradigm for modern intelligent systems because many applications require inference that is fast, private, local, and resilient to network limitations. Deploying models on devices is not simply a smaller version of cloud inference; it is a distinct engineering problem shaped by memory, compute, energy, thermal, and platform constraints.
TensorFlow Lite provides an important toolchain for this problem by enabling compact model formats, lightweight runtime execution, hardware acceleration, and optimization techniques such as quantization. Understanding Edge AI therefore requires understanding both machine learning and systems engineering: model accuracy must be balanced against latency, footprint, battery cost, and real-world device behavior. When done well, edge deployment brings AI directly to the point of action and unlocks a wide range of practical, privacy-aware, and robust applications.



