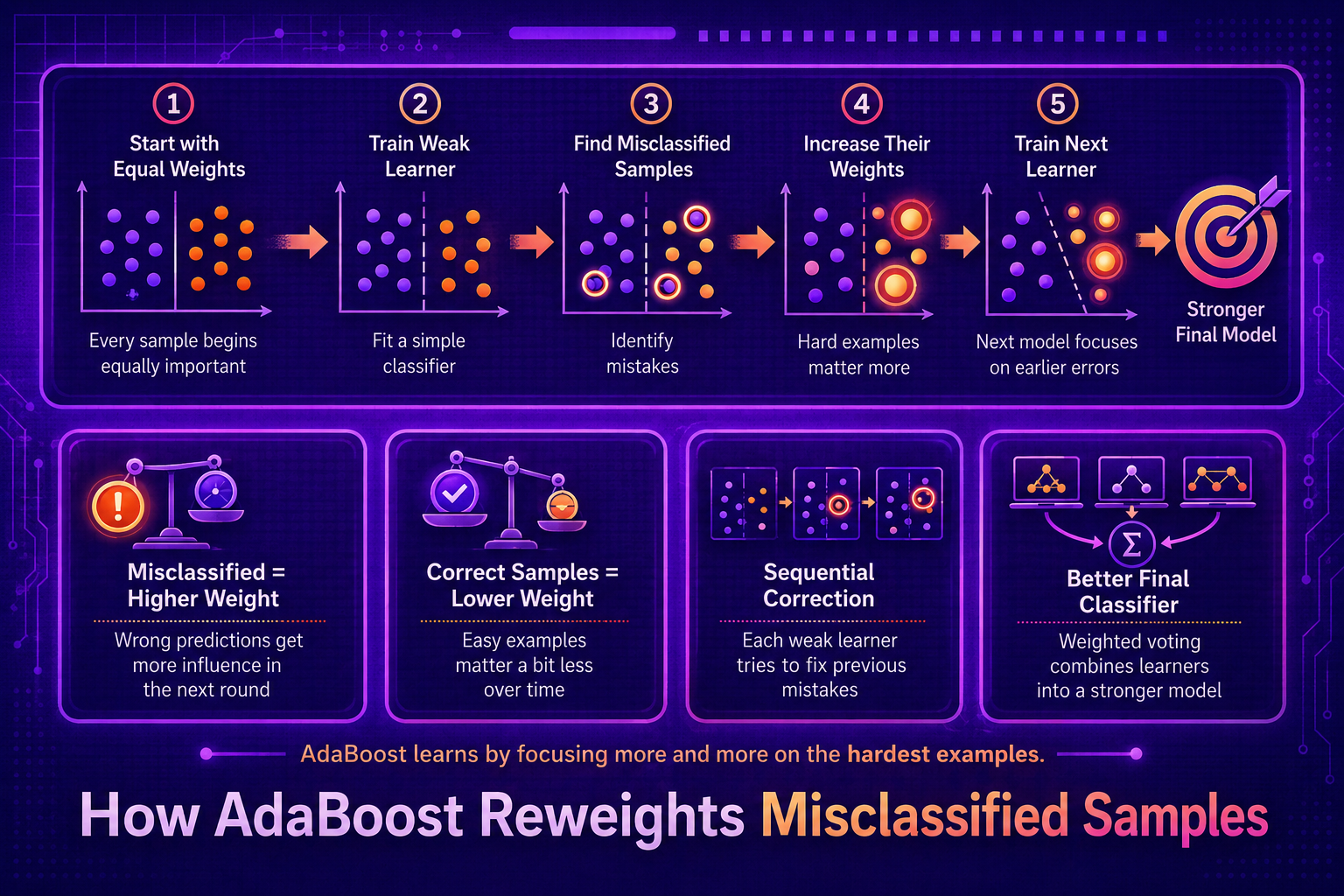
The sample reweighting step is AdaBoost’s most distinctive mechanism. After each boosting round, misclassified training examples receive higher weights and correctly classified examples receive lower weights, so the next learner must focus on the current ensemble’s hardest failures. This article dissects that update step with exact formulas, visualises how individual sample weights evolve across rounds, and shows what happens when the weight concentration becomes extreme — including the failure mode of noisy labels.
1. Problem Statement
When you run AdaBoostClassifier you get a final accuracy number, but the intermediate state — which samples had high weights at round 5, which ones drove the round 10 stump’s split, which ones accumulated pathologically high weights — is invisible. This opacity makes it hard to diagnose why a boosting run failed or why it performed differently on two similar datasets. Understanding the weight update step in detail gives you a precise mental model for boosting’s behaviour on clean data, noisy data, and class-imbalanced data.
2. Why This Matters
The reweighting mechanism is directly responsible for both AdaBoost’s strength and its main weakness. Its strength: it creates the complementarity between successive learners that drives down error. Its weakness: a mislabelled training example is a hard example by definition — it will never be classified correctly — so its weight grows exponentially until it dominates the distribution and corrupts later rounds. Visualising the weight trajectory makes this dynamic concrete and actionable.
3. The Approach
We implement the weight update from scratch on a small synthetic dataset, printing exact weight values at each round. We then scale to a larger dataset and visualise: (1) weight histograms across rounds, (2) cumulative weight share of the top-k hardest examples, (3) what happens when we inject label noise into specific samples and track their weight trajectory. The goal is to build a frame-by-frame understanding of a normally opaque algorithm.
4. Mathematical Foundation
At round t with current weights w(t), AdaBoost trains stump ht and computes the weighted error:
εt = Σi: ht(xi) ≠ yi wi(t)
The stump’s contribution weight is:
αt = (1/2) ln((1 − εt) / εt)
Sample weights are then updated. For a misclassified example (yi ht(xi) = −1):
wi(t+1) = wi(t) · exp(+αt)
For a correctly classified example (yi ht(xi) = +1):
wi(t+1) = wi(t) · exp(−αt)
After renormalisation so weights sum to 1, the ratio between a misclassified and a correctly classified example grows by a factor of exp(2αt) = (1 − εt) / εt per round. For εt = 0.3, this ratio is 7/3 ≈ 2.3 per round. After 10 rounds of persistent misclassification, a sample’s weight could be 2.310 ≈ 4,143 times its initial value — an extreme concentration that dominates the distribution entirely.
5. Algorithm Walkthrough
- Round 0: all N weights equal to 1/N.
- Round t: train stump on current weights; identify which examples it misclassifies; multiply misclassified weights by exp(+αt) and correct by exp(−αt); renormalise.
- Persistent misclassifications accumulate multiplicatively across rounds — their weight grows exponentially in T.
- If an example is correctly classified in round t but misclassified in round t+1, its net weight change depends on the α values of those two rounds.
The key insight: the update is multiplicative, not additive. Small per-round multipliers compound into large weight differentials over many rounds. This is why boosting is sensitive to label noise — a mislabelled example is always misclassified, so its weight multiplier is applied every single round.
6. Dataset
This article uses make_classification with 200 samples and 4 features — small enough to inspect individual sample weights at each round, large enough to show the statistical patterns. For the noise experiment, 5 randomly selected examples have their labels flipped to simulate mislabelling. Open Notebook
7. Implementation
The notebook runs a manual AdaBoost loop, recording the full N×T weight matrix. It then produces three key visualisations: a heatmap of log-weights across rounds (rows = samples, columns = rounds), a line plot of individual sample weight trajectories for hard vs easy examples, and a cumulative weight concentration plot showing how the top-10% of examples by final weight accumulate an ever-growing share of the total weight mass.
# Record full weight matrix
N, T = 200, 40
weight_matrix = np.zeros((T + 1, N))
weight_matrix[0] = 1.0 / N
for t in range(T):
stump = DecisionTreeClassifier(max_depth=1, random_state=t)
stump.fit(X_train, y_train, sample_weight=weight_matrix[t])
preds = stump.predict(X_train)
wrong = (preds != y_train_signed)
err = (weight_matrix[t] * wrong).sum()
alpha = 0.5 * np.log((1 - err) / (err + 1e-10))
w_new = weight_matrix[t] * np.exp(-alpha * y_train_signed * preds)
weight_matrix[t + 1] = w_new / w_new.sum()
8. Evaluation Approach
We evaluate along two dimensions: accuracy of the ensemble at each round (standard), and the statistical properties of the weight distribution at each round (novel). The latter includes the max weight, the Gini coefficient of the weight distribution (a measure of concentration), and the effective sample size ESS = 1 / Σ wi2 — which decreases as weights concentrate, quantifying the loss of effective training signal.
9. Results and Interpretation
On clean data with 200 samples, after 40 rounds the top 10 samples (5%) typically hold ~35–45% of the total weight. The ESS drops from 200 (uniform) to roughly 40–60 (20–30% of nominal), meaning the later stumps are effectively trained on only 40–60 informative examples despite having 200 in the dataset. On the noisy version (5 flipped labels), the 5 mislabelled examples accumulate ~60–70% of total weight by round 40, and test accuracy deteriorates visibly after round 20 — the classic noise overfitting signature.
10. Hyperparameter Considerations
The learning_rate (shrinkage factor ν) modulates the speed of weight concentration: smaller ν means αt is scaled down, reducing the per-round weight multiplier and slowing concentration. This is why lower learning rates are more noise-robust — weight concentration is the mechanism of noise sensitivity, and slower concentration delays the overfitting of noisy labels. The base estimator’s max_depth also matters: deeper trees misclassify fewer examples each round, leading to lower εt, higher αt, and faster weight concentration.
11. Comparison with Baseline
The notebook compares weight concentration (measured by ESS) against a bagging ensemble with the same number of rounds. Bagging uses bootstrap resampling, which is approximately uniform — the effective sample size stays near N regardless of round count. AdaBoost’s ESS falls monotonically. This quantifies the trade-off: AdaBoost focuses more aggressively but loses diversity in the process.
12. Strengths
- The multiplicative weight update creates an exponentially fast margin on easy examples — they rapidly receive negligible weight, letting the algorithm focus resources entirely on the hard boundary.
- The α-weighted combination ensures that rounds with lower error contribute proportionally more to the final vote — a principled quality gate that emerges from the theory without requiring a separate validation step.
- The weight distribution’s concentration is self-limiting in the absence of noise: once the hardest examples are correctly handled (stump can split them), their weights stop growing.
13. Limitations
- Exponential weight growth for persistently misclassified examples is the fundamental noise sensitivity. A single mislabelled example can accumulate 50% of total weight by round 30, collapsing the ensemble’s generalisation.
- The weight distribution is not inspectable during sklearn’s AdaBoostClassifier training — you must implement the loop manually to observe it, which adds debugging friction.
- Weight concentration reduces the effective diversity across rounds: later stumps are trained on essentially the same concentrated distribution, limiting the marginal benefit of additional rounds.
14. Common Failure Modes
- Pathological weight concentration from noisy labels. Symptom: test accuracy peaks early then declines. Fix: reduce learning_rate or switch to GradientBoostingClassifier with subsample < 1.
- All weight collapsing to a single example (numerical instability). Happens when εt is very close to 0 — one stump fits perfectly, αt becomes very large, and exp(αt) overflows. Fix: clip εt away from 0 and 1 before computing α.
- Ignoring the ESS as a diagnostic. A model that looks fine by accuracy metrics may have catastrophically concentrated weights — a sign that the later rounds are fitting noise. Monitor ESS alongside accuracy.
15. Best Practices
- Always inspect the staged test score curve. A test error that begins rising while training error continues falling is the definitive sign that weight concentration has reached the noise-overfitting regime.
- For noisy datasets, use learning_rate ≤ 0.1 to slow weight concentration and give the ensemble more rounds of useful learning before noise dominates.
- Monitor the maximum sample weight as a training diagnostic — if max(w) > 0.1 (10% of total weight on one example), the distribution has concentrated dangerously.
- If label noise is suspected, clean labels before boosting rather than trying to regularise around it. Boosting’s reweighting is fundamentally incompatible with systematic label error.
16. Conclusion
The weight update step is the heart of AdaBoost. Each round computes a multiplier that grows exponentially with the stump’s confidence (αt), applies it asymmetrically to misclassified versus correct examples, and renormalises. The result is a training distribution that concentrates progressively on the hardest examples. On clean data, this concentration is productive — it focuses all future rounds on the remaining errors. On noisy data, it is destructive — mislabelled examples receive runaway weights that corrupt the ensemble. Understanding this mechanism at the mathematical level is what lets you intervene effectively: slow the concentration with learning rate, detect it via ESS, and decide when noise sensitivity outweighs the bias-reduction benefit of additional rounds.



