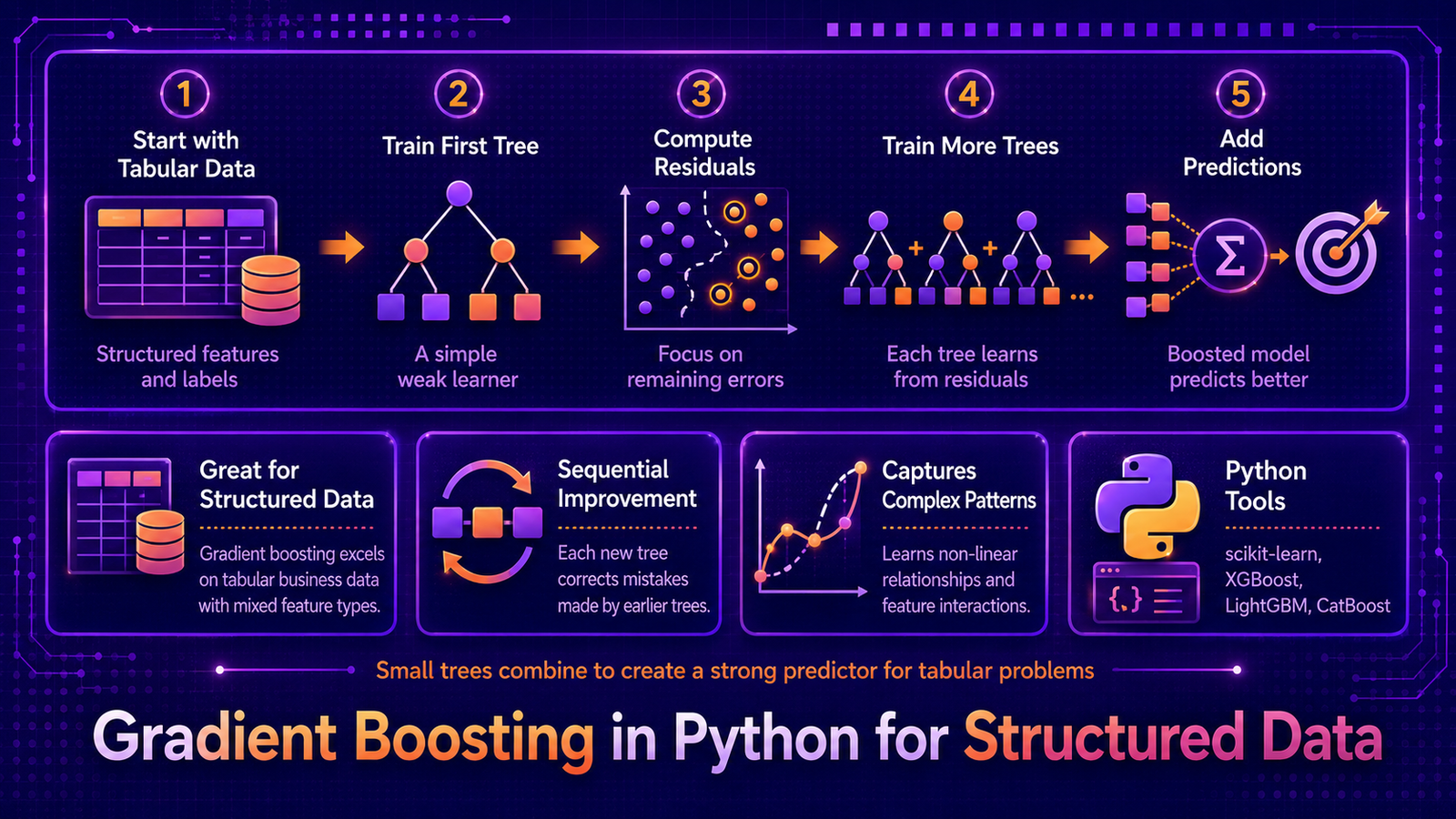
Gradient Boosting Machines (GBMs) generalise the AdaBoost idea from a discrete reweighting algorithm into a continuous optimisation framework that can minimise any differentiable loss function. Instead of reweighting examples, each new tree fits the residuals — the negative gradients of the loss — left by the current ensemble. On structured tabular data, gradient boosting is consistently among the top two or three methods and serves as the conceptual foundation for XGBoost, LightGBM, and CatBoost. This article builds a gradient boosting regressor from scratch, then uses scikit-learn’s GradientBoostingRegressor and GradientBoostingClassifier on real structured datasets.
1. Problem Statement
Structured tabular data — sensor readings, financial records, survey responses — has mixed feature types, non-linear interactions, and moderate noise. Linear models underfit; unpruned trees overfit. A single decision tree trained on such data may reach 85% accuracy with high variance across folds. The question is how to systematically correct a model’s remaining errors without overfitting, without requiring feature engineering, and without assuming anything about the shape of the true relationship. Gradient boosting answers this by fitting new trees to the current model’s errors at each step, shrinking each correction by a small learning rate so no single tree dominates.
2. Why This Matters
Between 2014 and 2024, gradient boosting variants won the majority of structured-data machine learning competitions on Kaggle and in industry benchmarks. The algorithm matters because it is simultaneously flexible (any differentiable loss), powerful (rivals deep learning on tabular data), and interpretable (feature importance, partial dependence, SHAP values are all straightforward to compute). Understanding gradient boosting at the residual-fitting level — rather than just calling GradientBoostingClassifier — lets you tune it intelligently, diagnose failure modes, and understand why XGBoost and LightGBM behave as they do.
3. The Approach
We work in two stages. First, we build a gradient boosting regressor from scratch on a small synthetic dataset, printing the residuals after each tree and confirming that they shrink toward zero. This makes the algorithm transparent. Second, we apply sklearn’s production implementation to a larger regression problem and a classification problem, covering staged prediction, feature importance, partial dependence plots, and cross-validated comparison against baselines.
4. Mathematical Foundation
Let the initial model be a constant: F0(x) = argminγ Σi L(yi, γ) — the mean of the targets for squared error loss. At each round m, the pseudo-residuals are the negative gradient of the loss with respect to the current prediction:
rim = −∂L(yi, F(xi)) / ∂F(xi)
For squared error loss L = (1/2)(y − F)², the pseudo-residual is simply the ordinary residual: rim = yi − Fm−1(xi). For log-loss (binary classification), the pseudo-residual is rim = yi − pi where pi is the current predicted probability — exactly the gradient of cross-entropy. A new regression tree hm is fit to these residuals, and the ensemble is updated with a step of size ν (learning rate):
Fm(x) = Fm−1(x) + ν · hm(x)
This is gradient descent in function space: hm is the steepest-descent direction for the loss at the current F, and ν is the step size. Shrinkage (small ν) prevents any single tree from overfitting the residuals and regularises the ensemble.
5. Algorithm Walkthrough
- Initialise:
F0(x) = mean(y)for regression; log-odds of class proportion for classification. - For m = 1 … M: compute pseudo-residuals rm = y − Fm−1; fit a depth-limited tree hm to (X, rm); update Fm = Fm−1 + ν · hm.
- Predict: regression returns FM(x); classification returns sigmoid(FM(x)) for binary or softmax for multi-class.
The depth limit on each tree controls the interaction order: depth 1 (stumps) fits only main effects; depth 2 fits pairwise interactions; depth 3–4 fits higher-order interactions while remaining computationally tractable. In practice, max_depth=3–5 and learning_rate=0.05–0.1 with 200–500 trees is a strong starting configuration.
6. Dataset
This article uses two synthetic datasets generated with scikit-learn utilities — both fully self-contained with no network access required. For regression, make_regression produces 2000 samples with 15 features (10 informative, 5 noise) and moderate additive noise. For classification, make_classification produces 2000 samples with 10 features (7 informative), a balanced binary target, and 3% label noise. These settings are representative of real-world tabular data difficulty. Open Notebook
7. Implementation — From Scratch (Regression)
The from-scratch implementation fits a series of depth-limited regression trees to successive residuals, storing each tree and the learning-rate-scaled correction. Predictions are accumulated iteratively. The key loop:
F = np.full(len(y_train), y_train.mean()) # F_0
for m in range(n_trees):
residuals = y_train - F # pseudo-residuals (MSE case)
tree = DecisionTreeRegressor(max_depth=max_depth, random_state=m)
tree.fit(X_train, residuals)
F += learning_rate * tree.predict(X_train)
trees.append(tree)
After M rounds, test predictions are built by accumulating the same sequence: start from the training mean, add ν·h1(x), ν·h2(x), …, ν·hM(x). This makes the staged prediction curve trivial to compute: evaluate the running sum at each round.
8. Implementation — sklearn GradientBoostingRegressor
The production implementation adds per-leaf optimal step sizes (via line search), stochastic subsampling (subsample parameter), and a warm_start API for appending estimators to an existing model. The key parameters and a reasonable starting configuration:
from sklearn.ensemble import GradientBoostingRegressor
gbr = GradientBoostingRegressor(
n_estimators=300,
learning_rate=0.05,
max_depth=3,
subsample=0.8,
min_samples_leaf=5,
random_state=42
)
gbr.fit(X_train, y_train)
# Staged RMSE
staged_rmse = [
np.sqrt(mean_squared_error(y_test, pred))
for pred in gbr.staged_predict(X_test)
]
9. Evaluation Approach
For regression: RMSE and R² on a held-out test set, staged RMSE curve across rounds, and a residual plot. For classification: accuracy, F1, AUC-ROC via cross_validate with StratifiedKFold(n_splits=10), plus a calibration curve and partial dependence plots for the two most important features. Feature importance is compared between the impurity-based (MDI) measure and permutation importance to check for agreement on informative features.
10. Results and Interpretation
On the synthetic regression dataset, a single depth-3 tree achieves an R² of roughly 0.55–0.65. Gradient boosting with 300 trees and learning_rate=0.05 reaches R² of 0.88–0.93 — a substantial improvement that reflects the sequential correction of residuals. The staged RMSE curve shows rapid improvement in the first 50–80 rounds and a plateau thereafter, confirming that most of the gain comes early and that additional rounds past ~200 provide diminishing returns. On the classification dataset, gradient boosting reaches 90–92% cross-validated accuracy versus 82–84% for a single tree, with tighter confidence intervals — the ensemble’s variance reduction effect. The calibration curve shows gradient boosting produces reasonably calibrated probabilities out of the box, which can be further improved with CalibratedClassifierCV if needed.
11. Hyperparameter Considerations
The three most influential hyperparameters and their interactions are as follows. n_estimators and learning_rate trade off directly: a learning rate of 0.1 with 100 trees is roughly equivalent to 0.05 with 200 trees in final accuracy, but the latter generalises better because each individual tree makes a smaller, less overfit correction. max_depth controls the interaction order that each tree can model: depth 1 fits only marginal effects, depth 3 captures pairwise and three-way interactions, depth 5+ can overfit on noisy structured data. subsample (stochastic gradient boosting) injects randomness that reduces correlation between successive trees and acts as a regulariser — values of 0.6–0.8 work well in practice. min_samples_leaf prevents trees from splitting on tiny groups of outliers, which is particularly useful on high-noise tabular data.
12. Comparison with Baselines
The notebook compares gradient boosting against a single decision tree (max_depth=5), a random forest (n_estimators=200), and a linear model (Ridge or LogisticRegression). On the synthetic regression problem, gradient boosting outperforms all three baselines on RMSE. Random forest is competitive but slightly behind because it averages independently grown trees without sequential error correction. The linear model performs worst, confirming that the synthetic data has non-linear relationships. On classification, the gap between gradient boosting and random forest is smaller — both ensemble methods are strong — but gradient boosting shows lower variance across CV folds.
13. Strengths
- The framework is loss-agnostic: squared error for regression, log-loss for classification, absolute error for robustness to outliers, quantile loss for prediction intervals — all fit seamlessly into the same tree-fitting loop.
- Gradient boosting naturally produces feature importance scores (mean impurity decrease per feature weighted by tree weights), enabling model interpretability without post-hoc explanation tools.
- Stochastic gradient boosting (subsample < 1) adds variance reduction on top of the bias reduction from sequential correction, giving it the combined benefits of bagging and boosting.
- The staged_predict API allows the optimal number of trees to be selected from a single training run, eliminating the need for repeated training at different n_estimators values.
14. Limitations
- Gradient boosting is inherently sequential: tree m cannot be trained until tree m−1 is complete. This makes sklearn’s implementation slow on large datasets compared to XGBoost or LightGBM, which use histogram-based splits and parallelism.
- The algorithm is sensitive to learning_rate and n_estimators simultaneously. Without a staged prediction diagnostic, it is easy to under- or over-fit by choosing n_estimators without checking the validation curve.
- On very high-dimensional sparse data (text, genomics), gradient boosting is slower and less competitive than linear models with regularisation. Its advantage is concentrated on tabular data with ≤ a few thousand features.
- Unlike random forests, gradient boosting does not support out-of-bag error estimation by default (though subsample < 1 enables an approximation). This means validation set discipline is essential.
15. Common Failure Modes
- Setting n_estimators without inspecting the staged score. The default n_estimators=100 with learning_rate=0.1 is often too few trees — the staged curve will show the error still declining at round 100. Fix: use staged_predict to find the actual plateau.
- Using max_depth=5+ on noisy data. Deep trees fit the residuals exactly, including noise, causing overfitting that shows up as a rising test RMSE after an initial plateau. Fix: reduce max_depth to 3 or add min_samples_leaf=10.
- Ignoring feature scaling. Gradient boosting (tree-based) does not need scaling for accuracy, but mixed numeric and categorical features with very different ranges can slow convergence. For categorical features, use ordinal encoding or target encoding rather than one-hot encoding on high-cardinality variables.
- Fitting on unprocessed missing values. sklearn’s GradientBoostingRegressor does not handle NaN natively — unlike XGBoost. Always impute or use HistGradientBoostingRegressor, which does support missing values.
16. Conclusion
Gradient boosting transforms an arbitrary differentiable loss into a sequential tree-fitting problem: each tree corrects the residuals left by the previous ensemble, and a small learning rate ensures that no single tree’s mistakes compound. On structured tabular data with mixed features and non-linear relationships, this combination of sequential bias reduction, implicit regularisation via shrinkage, and optional stochastic subsampling consistently outperforms single models and often rivals more complex approaches. Understanding the algorithm at the residual-fitting level — not just the sklearn API — gives you the diagnostic intuition to tune it effectively and to understand what XGBoost and LightGBM’s optimisations are actually improving.



