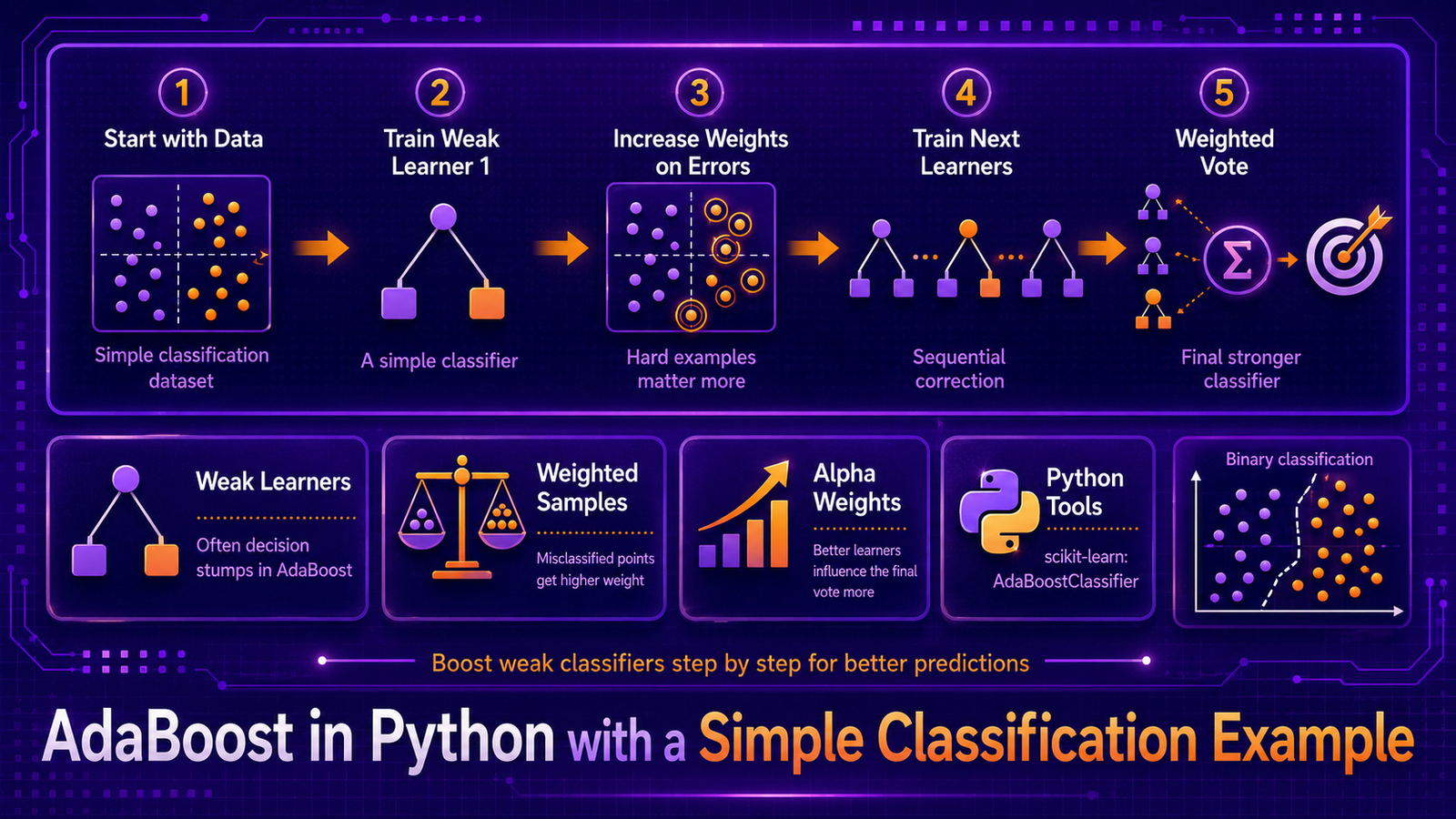
AdaBoost (Adaptive Boosting) was the first practical implementation of the boosting idea. It builds a strong classifier from an ensemble of decision stumps by sequentially reweighting training examples: correctly classified examples lose weight, misclassified examples gain weight, forcing each successive stump to focus on the previous one’s hardest errors. This article implements AdaBoost end-to-end on the Iris dataset, visualises its decision boundaries, and compares it against single-model baselines.
1. Problem Statement
Classifying iris species from petal and sepal measurements sounds simple — and for two classes it nearly is. But a pure linear classifier or a single decision stump makes systematic errors on the decision boundary between species. AdaBoost solves this by adding stumps that specifically target boundary examples, gradually sharpening the decision boundary without increasing model complexity the way a deeper tree would.
2. Why This Matters
AdaBoost is historically important because it proved the boosting hypothesis: weak learning is sufficient for strong learning. Practically, it is still competitive on clean, balanced datasets and serves as the conceptual foundation for gradient boosting. Understanding exactly how AdaBoost’s decision boundary evolves as stumps are added gives you the intuition to diagnose and tune any boosting algorithm.
3. The Approach
We use the Iris dataset with two selected classes (a binary problem) and two features so decision boundaries can be plotted in 2D. We train AdaBoost with 1, 5, 10, 30, and 100 rounds and plot the boundary at each stage, making the sequential refinement visually obvious. We then scale to the full 3-class problem using SAMME (AdaBoost’s multi-class extension) and evaluate with all standard metrics.
4. Mathematical Foundation
For binary classification with labels y ∈ {−1, +1}, AdaBoost minimises the exponential loss:
L = Σi=1N exp(−yi · F(xi))
where F(x) = Σt=1T αt ht(x) is the ensemble margin. Each boosting round performs a one-step coordinate descent on this loss by choosing the stump ht that most reduces L. The optimal stump weight is:
αt = (1/2) ln((1 − εt) / εt)
For multi-class with K classes, the SAMME algorithm extends this with:
αt = ln((1 − εt) / εt) + ln(K − 1)
The extra term ln(K − 1) accounts for the baseline error of a K-class random guesser. SAMME.R (the scikit-learn default) uses class probability estimates instead of hard predictions, typically converging faster and achieving lower final error.
5. Algorithm Walkthrough
- Initialise: uniform weights
wi = 1/N. - For t = 1 … T: fit stump ht on weighted data; compute weighted error εt; compute αt; update weights (misclassified ↑, correct ↓); normalise.
- Predict:
H(x) = argmaxk Σt αt · 𝟙[ht(x) = k].
For SAMME.R, the update uses log-probability contributions from each class, giving smoother probability estimates than the discrete SAMME vote.
6. Dataset
This article uses the Iris dataset from scikit-learn: 150 samples, 4 features (sepal length/width, petal length/width), 3 classes (setosa, versicolor, virginica). For boundary visualisation we use petal length and petal width — the two most discriminating features. For the full classification experiment we use all four features. Open Notebook
7. Implementation
The notebook trains AdaBoostClassifier with SAMME.R (default) across multiple round counts, plots decision boundaries in 2D for the binary sub-problem, generates a full classification report for the 3-class problem, and compares SAMME vs SAMME.R convergence curves.
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
ada = AdaBoostClassifier(
estimator=DecisionTreeClassifier(max_depth=1),
n_estimators=100,
learning_rate=1.0,
algorithm='SAMME',
random_state=42
)
ada.fit(X_train, y_train)
8. Evaluation Approach
For the binary problem: accuracy, F1, AUC-ROC, and the decision boundary visualisation. For the 3-class problem: macro-averaged precision, recall, F1, and a confusion matrix. We also plot the staged score (accuracy at each round) to identify the optimal number of estimators for this dataset, and a calibration plot to assess whether SAMME.R’s probability outputs are trustworthy.
9. Results and Interpretation
On the binary Iris sub-problem (versicolor vs virginica), a single stump achieves ~80% accuracy on the test set. After 10 AdaBoost rounds the boundary tightens to ~92%. After 100 rounds accuracy reaches ~96–98%. The boundary plots show the characteristic progression: early rounds create coarse, axis-aligned splits; later rounds add fine-grained corrections near the decision boundary where the two classes overlap. For the full 3-class problem, AdaBoost typically achieves 95–97% accuracy, matching or slightly exceeding a full unpruned decision tree while being more stable across CV folds.
10. Hyperparameter Considerations
n_estimators and learning_rate are the two primary knobs, and they interact: a learning_rate of 1.0 with 100 estimators is roughly equivalent to learning_rate of 0.5 with 200 estimators in terms of total shrinkage. Lower learning rates are more robust but require more estimators. The algorithm parameter (SAMME vs SAMME.R) matters: SAMME.R converges faster because it uses probability information; SAMME is simpler and works with any weak learner that outputs hard class labels.
11. Comparison with Baseline
The notebook compares AdaBoost against a single decision stump (worst baseline), a full unpruned decision tree (strong single model), and logistic regression (linear baseline). AdaBoost’s CV accuracy is consistently higher than all three, with lower variance than the single tree. Logistic regression is competitive on this linearly near-separable dataset — illustrating that AdaBoost’s advantage is largest when the decision boundary is genuinely non-linear.
12. Strengths
- AdaBoost has theoretical generalization guarantees: the training error decreases exponentially with rounds under the weak learner assumption, and the test error continues to improve even after training error reaches zero (due to margin maximisation).
- It is parameter-light compared to gradient boosting: learning_rate and n_estimators are the only primary controls.
- SAMME.R produces well-calibrated class probabilities, making AdaBoost suitable for applications that require probability thresholding.
- With decision stumps, AdaBoost is computationally efficient — each round trains a model that makes exactly one split.
13. Limitations
- AdaBoost is sensitive to label noise: mislabelled examples receive increasing weights, causing the ensemble to overfit them specifically.
- The exponential loss function heavily penalises misclassifications, making AdaBoost less robust to outliers than gradient boosting with a Huber or quantile loss.
- It cannot be parallelised across rounds — each round depends on the previous weight update.
- The SAMME.R variant requires base estimators that output class probabilities; this limits the choice of base learner.
14. Common Failure Modes
- Choosing learning_rate = 1.0 with many rounds on a noisy dataset. The ensemble overfits the mislabelled examples. Fix: reduce learning_rate to 0.1–0.5 and monitor staged test error.
- Using max_depth > 1 for base estimators. Deeper trees introduce their own variance and can dominate later rounds, destabilising the weight distribution.
- Not checking staged_score for the optimal round count. The default n_estimators may be too large (overfitting) or too small (underfitting) for the specific dataset.
- Assuming AdaBoost handles multi-class natively without checking the algorithm parameter. SAMME must be specified explicitly when base learners do not output probabilities.
15. Best Practices
- Always plot staged test score to find the optimal round count before committing to a fixed n_estimators value.
- Use SAMME.R (sklearn default) when probability outputs are needed; use SAMME when working with base learners that do not support predict_proba.
- Start with learning_rate=1.0 for quick experiments; reduce to 0.1–0.5 for final models on noisy data.
- On imbalanced datasets, combine class_weight=’balanced’ in the base DecisionTreeClassifier with AdaBoost to prevent the majority class from dominating the weighted error at each round.
- Cross-validate the full pipeline (preprocessing + AdaBoost) to get honest performance estimates — AdaBoost’s many rounds can implicitly overfit to a single validation split.
16. Conclusion
AdaBoost translates the abstract boosting theorem into a practical algorithm: train a stump, compute its weighted error, reweight the training data, repeat. The result is a classifier whose decision boundary progressively tightens around the hard examples in the dataset, without requiring hand-crafted features or explicit regularisation. On clean, balanced datasets, AdaBoost with depth-1 stumps is competitive with much more complex models while remaining interpretable at the level of individual stumps and their weights.
The next article in this series dissects the weight update step in detail — showing exactly which samples gain weight, by how much, and why this creates the complementarity that makes AdaBoost work.



