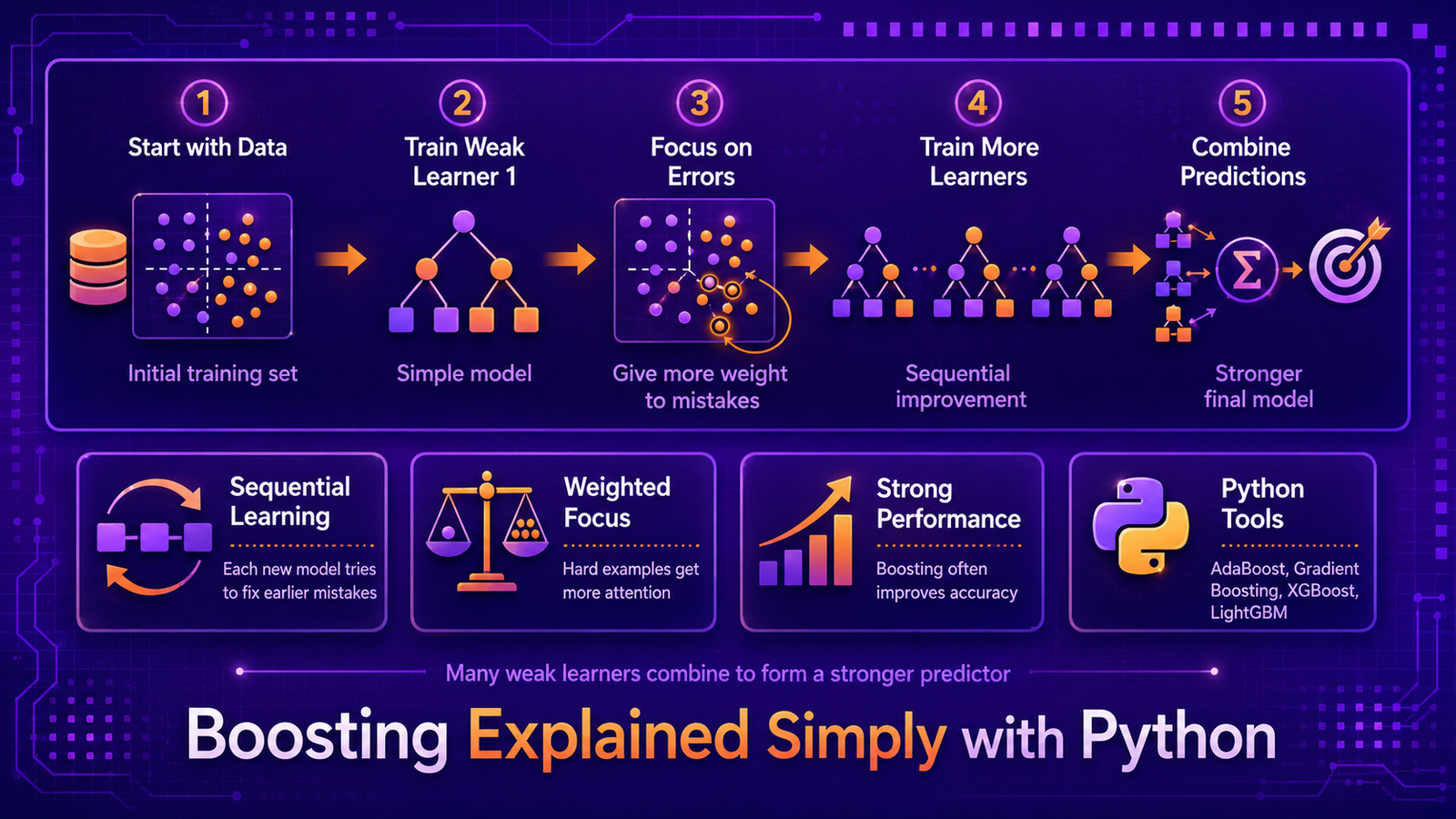
Boosting is the idea that many weak learners — models that are only slightly better than random guessing — can be combined sequentially to form a strong learner. Each model in the sequence focuses on the examples the previous model got wrong. This article builds the intuition from scratch, shows the math that makes it work, and implements a minimal boosting loop in Python before introducing scikit-learn’s production-ready version.
1. Problem Statement
A single decision stump — a tree of depth 1 that makes one binary split — performs only slightly better than random guessing on most real datasets. It is too simple to capture complex patterns. But simple models are cheap to train, easy to interpret, and unlikely to overfit. The challenge: can we combine many stumps in a way that produces a model as accurate as a complex deep tree, while inheriting the stumps’ robustness and speed?
Boosting answers yes. The key insight is sequential correction: each stump is trained not on the original labels but on the residuals or reweighted examples from the previous round, forcing it to focus exactly where the current ensemble is failing. The stumps are complementary by construction.
2. Why This Matters
Understanding boosting from first principles matters for two reasons. First, it explains why gradient boosting variants (XGBoost, LightGBM, CatBoost) dominate structured-data competitions and production pipelines — the mechanism is directly traceable to the sequential correction idea. Second, it gives you the vocabulary to diagnose boosting failures: too many rounds causes overfitting because the model starts correcting noise; too few rounds leaves systematic bias uncorrected. Without the mechanism, these failure modes look mysterious.
3. The Approach
We build intuition in three layers. First, a single stump trained on the original data — demonstrating its inherent weakness. Second, a hand-written boosting loop of 10 stumps, showing how error decreases round by round. Third, scikit-learn’s AdaBoostClassifier with 200 rounds, showing how the same idea scales to production quality. Throughout, we track the two quantities that matter: training error (does the ensemble capture the signal?) and test error (does it generalise?).
4. Mathematical Foundation
At round t, boosting trains a weak learner ht and combines it with the existing ensemble. The final prediction aggregates all T learners with learned weights αt:
H(x) = sign(Σt=1T αt ht(x))
The weight αt reflects how good learner t is: better learners get higher weight. In AdaBoost:
αt = (1/2) ln((1 − εt) / εt)
where εt is the weighted error of ht. If εt = 0.5 (random), αt = 0. If εt → 0 (perfect), αt → ∞. The sample weights for the next round are then updated: misclassified examples get higher weight, correctly classified examples get lower weight:
wi(t+1) = wi(t) · exp(αt · 𝟙[ht(xi) ≠ yi])
After renormalisation, the next stump is trained on a distribution that emphasises the hardest examples. This is the core mechanism: boosting is gradient descent in function space, where each round takes a step in the direction that most reduces the exponential loss.
5. Algorithm Walkthrough
- Initialise sample weights:
wi(1) = 1/Nfor all i. - For t = 1 to T: train ht on weighted data; compute weighted error εt; compute learner weight αt; update and renormalise sample weights.
- Final prediction:
H(x) = sign(Σt αt ht(x)).
The key invariant: at every round, εt < 0.5 is guaranteed as long as the base learner is better than random on the current weight distribution. This is why “weak learner” is a precise requirement — slightly better than chance is all that is needed.
6. Dataset
This article uses make_classification from scikit-learn with 1,000 samples, 10 features (6 informative), and a binary target. The dataset is designed to be non-trivially separable — a single stump cannot achieve more than ~75% accuracy, making the sequential improvement from boosting clearly visible. Open Notebook
7. Implementation
The notebook implements a minimal AdaBoost loop from scratch in ~30 lines, then compares it to scikit-learn’s AdaBoostClassifier. The from-scratch version makes weight updates and learner combination explicit, while the sklearn version adds production features like SAMME.R probability estimation.
# Minimal AdaBoost from scratch
weights = np.ones(N) / N
alphas, stumps = [], []
for t in range(n_rounds):
stump = DecisionTreeClassifier(max_depth=1)
stump.fit(X_train, y_train, sample_weight=weights)
preds = stump.predict(X_train)
err = weights[preds != y_train].sum()
alpha = 0.5 * np.log((1 - err) / (err + 1e-10))
weights *= np.exp(-alpha * y_train * preds)
weights /= weights.sum()
alphas.append(alpha); stumps.append(stump)
8. Evaluation Approach
We plot the staged training and test error across boosting rounds — the most informative diagnostic for boosting. Training error should decrease monotonically. Test error should decrease then plateau (well-regularised) or eventually increase (overfitting). We also compare the confusion matrices of a single stump, the 10-round hand-written ensemble, and the full 200-round sklearn AdaBoost.
9. Results and Interpretation
A single decision stump typically achieves ~72–76% accuracy on this dataset. After 10 boosting rounds (from-scratch), accuracy rises to ~83–86%. After 200 rounds with AdaBoostClassifier, accuracy reaches ~90–93%. The improvement is monotone and largely predictable: each round fills in a different region of the error landscape. The staged error plot shows training error converging to near zero while test error stabilises well above it — the signature of a well-regularised ensemble.
10. Hyperparameter Considerations
The two most important hyperparameters are n_estimators (number of boosting rounds) and learning_rate. These trade off against each other: halving the learning rate requires roughly doubling n_estimators to achieve the same training error. Lower learning rates generally produce better-generalising models but require more rounds. The base estimator’s max_depth is a third dial — deeper stumps increase individual accuracy but reduce diversity across rounds; depth 1 (stumps) is the standard starting point.
11. Comparison with Baseline
The notebook plots accuracy versus number of rounds for the boosted ensemble against three flat baselines: random guessing (50%), a single stump (≈74%), and a full unpruned decision tree (≈87%). Boosting surpasses the single tree accuracy by round ~30–50 and continues improving until it plateaus. The full tree, despite its complexity, is volatile across cross-validation folds; the boosted ensemble is substantially more stable.
12. Strengths
- Boosting systematically reduces bias — the sequential correction mechanism directly targets systematic errors left by the current ensemble.
- Decision stumps as base learners are extremely fast to train (O(N log N) per round), so even 500-round ensembles train in seconds on moderate datasets.
- The learner weight αt provides a natural quality gate: rounds that produce near-random learners contribute negligible weight to the ensemble.
- Boosting generalises well in theory: Schapire’s boosting bound guarantees exponential decrease in training error as rounds increase, under the weak learner assumption.
13. Limitations
- Boosting is sensitive to noisy labels. Mislabelled examples are systematically hard and receive ever-increasing weights, causing the ensemble to overfit them.
- Sequential training cannot be parallelised across rounds — each round depends on the previous one’s weight updates. This is a fundamental difference from bagging, which is embarrassingly parallel.
- Outliers in the feature space receive increasing weights even if their labels are correct, because stumps cannot fit them well. This can cause instability in later rounds.
- Learning rate requires tuning. Too high and the ensemble overfits quickly; too low and many rounds are needed, increasing training time.
14. Common Failure Modes
- Running too many rounds without regularisation. If learning_rate is high and n_estimators is large, training error reaches zero but test error rises — classic overfitting. Use staged_score to find the optimal round.
- Using a strong base learner (deep trees) instead of stumps. Deep trees introduce their own variance, which compounds across rounds rather than being corrected.
- Skipping cross-validation for n_estimators selection. The optimal round count is dataset-specific; tuning on the test set invalidates the performance estimate.
- Ignoring class imbalance. AdaBoost’s weight update treats all misclassifications equally; on imbalanced data, the majority class dominates the error and the minority class never gets adequately focused on.
15. Best Practices
- Start with depth-1 stumps and learning_rate=0.1; increase n_estimators until staged test error plateaus.
- Use staged_score (available on AdaBoostClassifier) to find the optimal round without retraining.
- For noisy data, use GradientBoostingClassifier instead of AdaBoost — its shrinkage and subsampling provide better noise robustness.
- Always evaluate with stratified cross-validation — a single train/test split hides the variance in boosting’s performance across folds.
- Monitor both training and test error across rounds simultaneously. A widening gap signals overfitting; a persistent plateau on both signals underfitting (increase model capacity or add rounds).
16. Conclusion
Boosting transforms weak learners into strong ones through sequential correction. The mechanism is mathematically precise: at each round, misclassified examples receive higher weight, forcing the next learner to focus on the current ensemble’s hardest errors. The final prediction is a weighted vote where better rounds contribute more. This single idea — focusing on mistakes — is responsible for the empirical dominance of gradient boosting variants across nearly every structured-data benchmark in modern machine learning.
The next articles in this series implement AdaBoost in depth, dissect its sample-reweighting mechanism step by step, and then move to gradient boosting, which extends the same sequential-correction idea to arbitrary differentiable loss functions.



