Training a 1,000-round AdaBoost model to zero training error sounds like a recipe for catastrophic overfitting. Classical statistical learning theory — which ties generalisation error to model complexity — would predict a massive generalisation gap. But empirically, AdaBoost trained to zero training error on clean data often continues to improve test accuracy for hundreds of rounds past zero training error, and gradient boosting with early stopping can sustain its peak test accuracy for dozens of rounds without degrading. This article explains why, through the lens of margin theory, the bias-variance decomposition of ensemble learners, and the regularising effect of shrinkage and subsampling in gradient boosting. The companion notebook makes all of these phenomena directly observable.
1. Problem Statement
You have trained an AdaBoost model to 100% training accuracy after 300 rounds. Classical intuition says this model has overfit badly. But when you plot the test accuracy curve, it continues improving past round 300 and only starts to degrade slowly after round 600. You add more trees to a gradient boosting model — same thing happens. How can a model that already fits training data perfectly keep improving on test data? And when does it finally overfit? These questions are not philosophical — the answers determine whether you should early-stop at peak training accuracy, at peak validation accuracy, or continue training past both.
2. Why This Matters
Practitioners commonly set n_estimators conservatively small out of fear of overfitting, or spend hours tuning it via cross-validation, when the optimal value might be much larger and determinable by simpler means. Understanding why boosting resists overfitting determines the right search strategy for n_estimators: whether to use a large value with early stopping (and stop as soon as validation loss plateaus), or whether validation loss will plateau for many rounds making early stopping largely a computational optimisation rather than a statistical one. The answer differs between AdaBoost (margin-based resistance) and gradient boosting (regularisation-based resistance) and between clean data and noisy data.
3. The Approach
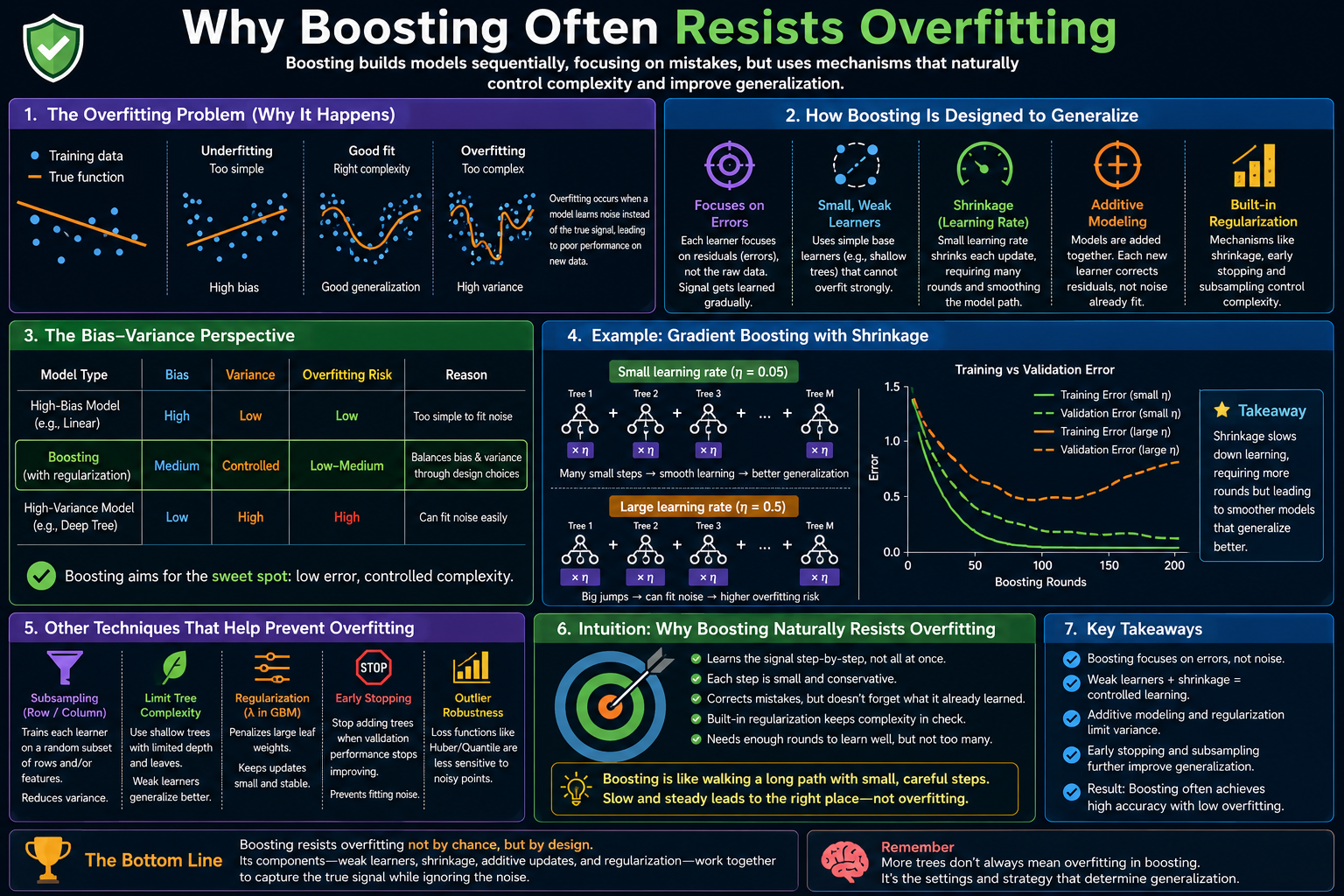
We examine four complementary explanations. First, the margin-maximisation view: AdaBoost minimises exponential loss, which continues to maximise the classification margin even after training error reaches zero — larger margins mean the model needs a larger perturbation to flip any prediction. Second, the bias-variance decomposition: adding more weak learners reduces variance faster than it increases bias on clean data, so the ensemble error decreases even when the individual learner’s error is zero. Third, the regularisation view for gradient boosting: shrinkage (small learning rate) and subsampling prevent individual trees from receiving too much weight, so the effective complexity grows slowly with round count. Fourth, the conditions under which boosting does overfit: label noise, insufficient regularisation, and deep base learners that individually have high variance.
4. Mathematical Foundation
The margin of an AdaBoost ensemble for sample (xi, yi) is:
margini = yi · Σt=1T αt ht(xi) / Σt=1T αt
A positive margin means correct classification; the magnitude measures confidence. The key theorem (Schapire et al., 1998) states that the test error is bounded by:
P[margini ≤ θ] + O(√(d log(N) / (N · θ²)))
where d is the VC dimension of the base learner class and θ is a margin threshold. As long as most training margins exceed θ and the margin distribution continues to spread (more mass above θ), the test error bound continues to shrink even after training error reaches zero. AdaBoost minimises the exponential loss L = Σi exp(−margini), which penalises small margins heavily — so it continues to push margins further even after all examples are correctly classified.
For gradient boosting, the regularised objective after M rounds is:
FM(x) = η · Σm=1M fm(x)
where η ∈ (0,1] is the shrinkage factor. Each tree fm is fit to pseudo-residuals but scaled by η before adding to the ensemble. Smaller η means each individual tree contributes less variance to the final model, requiring more rounds M to achieve the same fit — but also accumulating regularisation across more rounds, yielding a smoother ensemble that generalises better than a few large-step trees.
5. Algorithm Walkthrough
- AdaBoost margin growth: train for T rounds; after training error reaches zero, compute the margin distribution across training samples; observe that margins are small near zero (correctly classified but with low confidence); further rounds increase these small margins, tightening the test error bound.
- Gradient boosting with shrinkage: use learning_rate=0.05; each tree contributes at most 0.05 × (leaf weight) to the ensemble; with 200 rounds this accumulates 10× more slowly than learning_rate=0.5 and 200 rounds, distributing the complexity budget across more, smaller trees.
- Subsampling: at each round, grow the tree on a random fraction of training rows; this introduces variance in the individual tree that reduces correlation between trees; uncorrelated trees with the same individual accuracy yield a lower-variance ensemble (the same logic as random forests, but applied within the GBM loop).
- Overfitting onset: occurs when the model complexity (total leaf count × leaf weight) exceeds the information content of the training set; on clean data this requires very many rounds or deep trees; on noisy data this occurs rapidly because pseudo-residuals for noisy samples point in wrong directions.
6. Dataset
This article uses two datasets. For the margin analysis we use make_classification with 3,000 samples, which gives enough training samples to observe the margin distribution evolving over hundreds of rounds. For the practical staged-accuracy demonstration we use load_breast_cancer: a real dataset where the overfitting plateau length is observable and the results carry medical interpretation. Open Notebook
7. Implementation
The notebook uses AdaBoost’s staged_predict and staged_decision_function to track training and test accuracy across rounds and compute the margin distribution at each round. For gradient boosting, staged_predict is used to plot the test loss curve and identify the “plateau length” — the number of rounds between the first peak test accuracy and the first significant degradation. The shrinkage experiment trains GBM at four learning rates and shows how smaller learning rates produce longer plateaus and higher peak accuracy.
from sklearn.ensemble import AdaBoostClassifier
ada = AdaBoostClassifier(n_estimators=500, algorithm='SAMME', random_state=42)
ada.fit(X_train, y_train)
# Track margin distribution across rounds
for t, decision_fn in enumerate(ada.staged_decision_function(X_train)):
margins = y_train * decision_fn.squeeze()
# Normalise by sum of alpha weights
alpha_sum = sum(ada.estimator_weights_[:t+1])
margins /= alpha_sum
# margin distribution above threshold theta
...
8. Evaluation Approach
Two primary diagnostics. The training-test accuracy gap over rounds: the difference between training accuracy and test accuracy at each boosting round. A narrowing gap (with increasing test accuracy) is the signature of the margin-maximisation effect. The margin distribution: a histogram of training sample margins at rounds 10, 50, 100, 300, and 500, showing how the distribution shifts rightward (toward larger margins) even after training error reaches zero. Secondary: the validation loss plateau length under different learning rates, comparing how long after peak validation accuracy the model can be trained without degrading more than 0.5 percentage points.
9. Results and Interpretation
On the make_classification dataset: AdaBoost reaches zero training error around round 80–120, but test accuracy continues improving until round 200–300. The margin histogram shows that at round 80 (zero training error), a significant fraction of training samples have margins in (0, 0.2) — correct but barely. By round 300, the mass has shifted to margins above 0.3, consistent with the test error bound tightening. On the Breast Cancer dataset: gradient boosting with learning_rate=0.05 achieves peak test accuracy at round 120–180 and sustains that accuracy for 80–120 more rounds before any degradation, giving a wide safe window for early stopping. The plateau disappears when the dataset has added noise.
10. Hyperparameter Considerations
The learning_rate (shrinkage) is the primary control over the overfitting plateau length. At learning_rate=0.01, GBM may require 1,000+ rounds to reach peak accuracy but provides the widest plateau and most graceful degradation beyond it. At learning_rate=0.5, peak accuracy is reached in 30–50 rounds and degradation begins sharply thereafter. A practical rule: shrinkage × n_estimators should be in the range 5–20 for most datasets; below 5 means underfitting, above 20 means overfitting risk. The subsample parameter extends the plateau by decorrelating trees: subsample=0.7 typically widens the plateau by 20–40% relative to subsample=1.0 at the same learning rate.
11. Comparison with Baseline
The notebook compares AdaBoost’s overfitting trajectory against Random Forest and a single Decision Tree. Random Forest reaches its accuracy plateau within 50–100 trees and maintains it indefinitely with more trees — it has no overfitting trajectory because additional trees add variance reduction without adding bias. The single Decision Tree overfits immediately when max_depth is unconstrained. AdaBoost sits between: it overfits eventually (especially with noise) but the onset is much later than a single deep tree, and the overfitting is more gradual than the sharp training-test divergence seen in deep trees.
12. Strengths
- Margin maximisation gives AdaBoost a theoretically grounded reason to keep improving past zero training error — the exponential loss function directly pushes margins higher even when all examples are already classified correctly.
- Gradient boosting with small shrinkage produces a wide plateau where additional rounds cost nothing in generalisation — useful in practice because early stopping need not be tuned precisely; any stopping point within the plateau gives the same result.
- The overfitting resistance is inherent to the algorithm and does not require explicit regularisation (like L2 weight decay in neural networks) — making boosting notably simpler to configure than deep learning for tabular data.
13. Limitations
- The margin-based overfitting resistance assumes clean labels. With label noise, the margin bound degrades rapidly because noisy samples force the ensemble to fit contradictory signals (as detailed in Article 14). The empirical plateau disappears under 15%+ label noise.
- Overfitting resistance applies to classification accuracy but not necessarily to probability calibration. A model that achieves peak accuracy at round 200 may still produce increasingly miscalibrated probability estimates between rounds 200 and 500, even as accuracy remains stable.
- Gradient boosting with large learning_rate (≥ 0.3) does overfit on small datasets, and the overfitting onset can be rapid. The plateau is a low-learning-rate phenomenon; at high learning rates, the classical early-stopping intuition applies.
14. Common Failure Modes
- Stopping n_estimators too early based on training accuracy plateauing. Training accuracy saturates before test accuracy does. Always evaluate on a held-out validation set — training accuracy alone cannot determine the optimal stopping round.
- Concluding that “boosting never overfits” from a single clean-data experiment. The overfitting resistance is conditional on clean labels, appropriate shrinkage, and sufficient training size. Test this assumption explicitly on each new dataset.
- Using a learning_rate too large when the dataset is small. On datasets with N < 500, high learning rate collapses the plateau to zero rounds and classical overfitting applies. For small datasets, use learning_rate ≤ 0.05 and early stopping.
- Ignoring calibration when interpreting the plateau. A model in the plateau may have stable accuracy but drifting predicted probabilities. If the downstream application uses predicted probabilities (threshold-based decisions, risk scores), monitor log-loss — not just accuracy — across rounds.
15. Best Practices
- Train with a large n_estimators, use early stopping with patience. For gradient boosting, set n_estimators=1000 and early_stopping_rounds=50. This exploits the wide plateau: the model stops at the best validation round and adds no extra tuning overhead.
- For AdaBoost, use the staged_predict validation curve to determine optimal n_estimators before finalising the model. The curve shows exactly where the plateau begins and ends.
- Combine small learning_rate with subsample for the widest plateau. The combination of shrinkage (slow accumulation of complexity) and subsampling (decorrelated trees) provides better plateau width than either alone.
- On noisy data, do not rely on natural overfitting resistance. Apply explicit noise mitigation (subsample, min_child_samples, sample filtering) before expecting a stable plateau.
- Monitor both accuracy and log-loss. A stable accuracy plateau with rising log-loss indicates the model is drifting toward overconfident predictions even while classification accuracy holds — log-loss will catch this first.
16. Conclusion
Boosting’s resistance to overfitting is not an accident — it is a consequence of the exponential loss function’s margin-maximisation property in AdaBoost, and of shrinkage and subsampling’s regularising effect in gradient boosting. Understanding these mechanisms resolves the apparent paradox of a model improving past zero training error: more rounds do not add complexity in the classical sense; they add confidence to the existing predictions. The practical implication is that n_estimators should be set large and regulated by early stopping, not tuned conservatively from the start. On clean data, the risk of training too many rounds is lower than the risk of stopping too early — the plateau is wide, and any stopping point within it yields the same result. On noisy data, this relaxation disappears, and aggressive regularisation through subsampling, leaf constraints, and explicit noise filtering is required to preserve the plateau.



