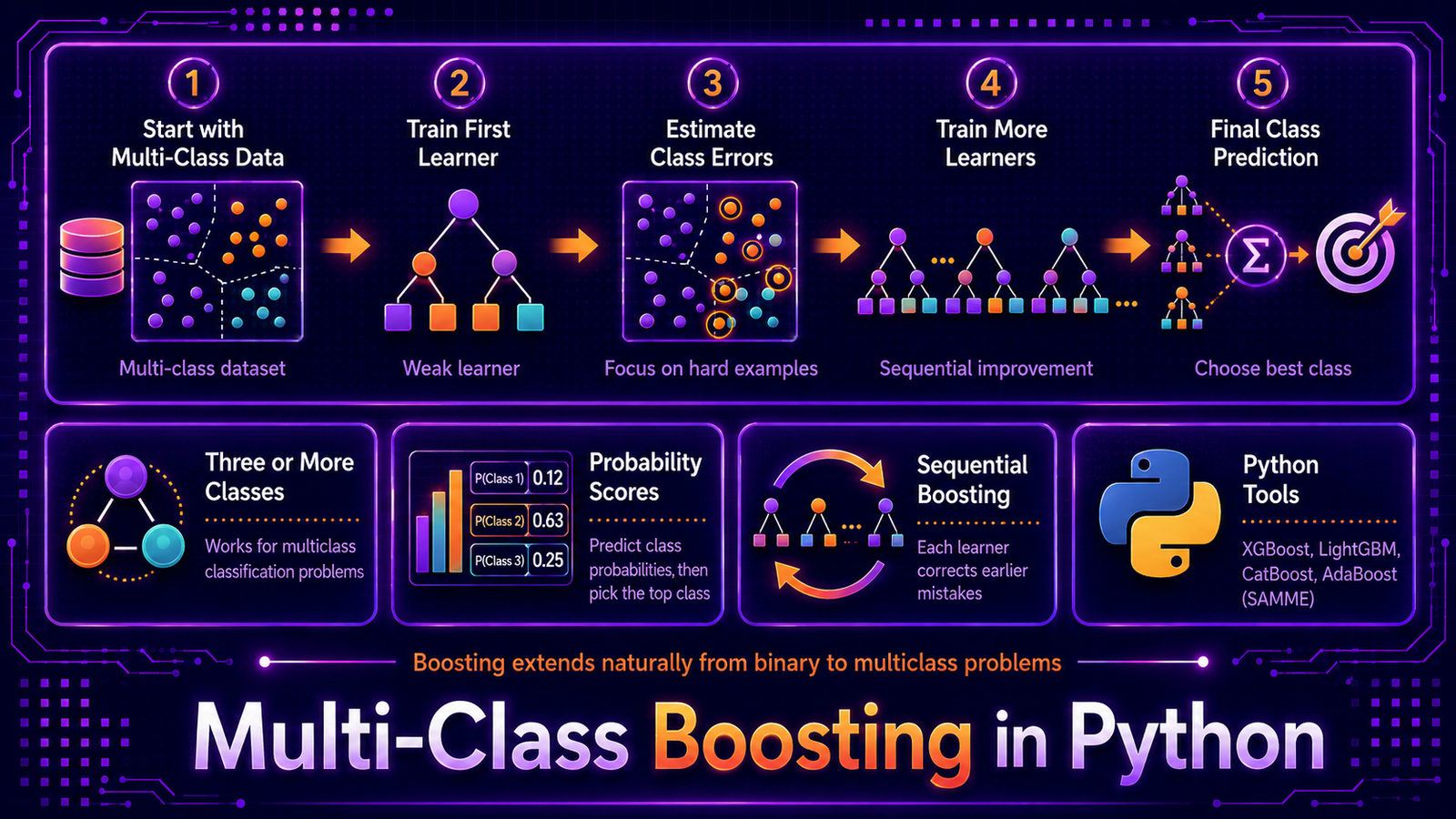
Binary boosting — AdaBoost, gradient boosting, XGBoost — is well understood, but most real classification tasks involve more than two classes: digit recognition, product categorisation, disease type diagnosis. Extending boosting to K > 2 classes requires a different loss function and a different way to compute the per-class gradients. This article explains SAMME (Stagewise Additive Modeling using a Multiclass Exponential loss), one-vs-rest gradient boosting, and the softmax gradient boosting approach used by XGBoost and LightGBM, then implements and compares all three on a concrete multi-class problem.
1. Problem Statement
You are building a document classifier that assigns incoming articles to one of eight topic categories. Binary AdaBoost cannot handle this directly — it expects labels in {−1, +1}. You could decompose the task into eight one-vs-rest binary classifiers, but each classifier then trains on heavily imbalanced data and the outputs are not directly comparable probabilities. Alternatively, you want a single boosting loop that jointly minimises a multi-class loss, producing a coherent K-dimensional probability vector for each document. This is the multi-class boosting problem.
2. Why This Matters
Naive decomposition strategies (one-vs-rest, one-vs-one) lose information by ignoring class relationships during training. SAMME extends AdaBoost’s exact theoretical framework to K classes by modifying the learner weight formula. Gradient boosting with softmax loss handles multi-class naturally by fitting K separate trees per round — one tree per class — and updating all K predictions jointly. Understanding which approach produces better-calibrated probability outputs and which runs faster on K-class problems helps you choose the right method for each project.
3. The Approach
We implement three strategies. First, SAMME (used by sklearn’s AdaBoostClassifier with algorithm=’SAMME’): a single boosting loop where the multi-class exponential loss is minimised by adjusting the learner weight formula to account for K classes. Second, one-vs-rest gradient boosting: K independent GBM models, each trained to predict “class k vs all others”, with final predictions from argmax of K raw scores. Third, native softmax gradient boosting: a single GBM with loss=’log_loss’ (sklearn) or objective=’multi:softmax’ (XGBoost/LightGBM), where K trees are grown per round and the softmax function normalises the K scores into a valid probability distribution.
4. Mathematical Foundation
SAMME modifies AdaBoost’s learner weight to account for the K-class baseline. The correct weight for a multi-class stump with weighted error εt is:
αt = ln((1 − εt) / εt) + ln(K − 1)
The extra ln(K − 1) term corrects for the fact that a random K-class guesser has error (K−1)/K, not 1/2. For K=2 the formula reduces exactly to binary AdaBoost’s αt = (1/2) ln((1−εt)/εt). The final prediction is the class with the largest cumulative weighted vote across all rounds.
For softmax gradient boosting, the ensemble maintains K score functions F1(x), …, FK(x). The predicted probability for class k is:
pk(x) = exp(Fk(x)) / Σj=1K exp(Fj(x))
The gradient for class k is the residual rik = 𝟙[yi=k] − pk(xi), and one regression tree per class is fit to these residuals at each round. This gives K × M trees in total for M boosting rounds.
5. Algorithm Walkthrough
- SAMME: initialise uniform weights; each round — train a single K-class stump; compute weighted error εt; compute αt using the multi-class formula; reweight samples (misclassified samples gain weight); repeat T rounds; predict via argmax of Σ αt ht(x).
- One-vs-rest GBM: train K binary GBMs independently; at inference, pick argmax of K predicted scores.
- Softmax GBM: initialise K = 0; each round, compute K gradient vectors; fit K trees; update K score functions; apply shrinkage; predict via softmax normalisation.
6. Dataset
This article uses two datasets. The primary dataset is the Wine dataset: 178 samples, 13 chemical measurements, 3 classes (cultivar types). Small enough for SAMME to train quickly and interpretable enough for EDA. For scale comparison, we also use load_digits: 1797 samples, 64 features (8×8 pixel images), 10 classes — a challenging multi-class problem where the class count forces learner weights to adjust substantially from the binary case. Open Notebook
7. Implementation
The notebook trains all three strategies and records accuracy, macro-F1, and cross-entropy on both datasets. SAMME is accessed via sklearn’s AdaBoostClassifier with algorithm=’SAMME’. Softmax GBM is accessed via GradientBoostingClassifier with loss=’log_loss’ (multi-class automatically when K>2). The notebook also plots the confusion matrix for each method and the staged accuracy curve for SAMME and softmax GBM.
from sklearn.ensemble import AdaBoostClassifier, GradientBoostingClassifier
# SAMME
samme = AdaBoostClassifier(
n_estimators=200, algorithm='SAMME', random_state=42
)
# Softmax GBM (native multi-class)
softmax_gbm = GradientBoostingClassifier(
n_estimators=200, learning_rate=0.1,
max_depth=3, loss='log_loss', random_state=42
)
8. Evaluation Approach
For the 3-class Wine dataset: accuracy, macro-averaged precision, recall, F1, and a 3×3 confusion matrix. For the 10-class digits dataset: same metrics plus a staged accuracy curve showing convergence across rounds. Cross-entropy (log-loss) is included as a calibration-aware metric — it penalises confident wrong predictions more than accuracy does. All comparisons use StratifiedKFold(10) for the final cross-validated estimate.
9. Results and Interpretation
On the Wine dataset (3 classes), all three methods achieve near-perfect accuracy (97–99%) because the classes are well separated in the 13-feature space. The key difference is in log-loss: softmax GBM produces well-calibrated probabilities (log-loss ≈ 0.08–0.12), while SAMME’s probability outputs are coarser since they come from the discrete α-weighted vote. On the Digits dataset (10 classes), softmax GBM typically achieves 95–97% accuracy, SAMME achieves 90–93%, and one-vs-rest GBM falls between them. The ln(K−1) correction in SAMME makes a measurable difference on 10-class problems — without it, the learner weights are inflated and convergence slows.
10. Hyperparameter Considerations
For SAMME, n_estimators is the primary knob — 100–300 stumps is usually sufficient for K ≤ 10 classes on clean data. The learning_rate parameter in sklearn’s AdaBoostClassifier scales αt and acts as a shrinkage factor. For softmax GBM, max_depth becomes more important than in binary GBM because each round fits K trees — deeper trees increase computation quadratically with K. For K=10, max_depth=2–3 is typically the right balance between expressiveness and overfitting. subsample (row subsampling) is especially useful for multi-class because it prevents the K trees at each round from all overfitting the same hard examples.
11. Comparison with Baseline
The notebook compares all boosting strategies against a single Decision Tree (max_depth=3), a Random Forest (100 trees), and Logistic Regression with multi-class=’multinomial’. On the Wine dataset, all methods match Logistic Regression (which is near-optimal for a linearly separable 3-class problem). On Digits, softmax GBM outperforms Logistic Regression by 2–4 percentage points and matches Random Forest — both capture the non-linear pixel interactions that Logistic Regression misses. SAMME underperforms softmax GBM because AdaBoost’s exponential loss is less suitable than cross-entropy for multi-class probability estimation.
12. Strengths
- Softmax GBM produces coherent, well-calibrated K-dimensional probability vectors in a single unified training loop — no post-hoc calibration or argmax heuristics needed.
- SAMME is theoretically grounded in multi-class exponential loss and gives interpretable learner weights with a closed-form correction for any K.
- Native softmax in XGBoost/LightGBM scales to large K with GPU support and histogram-based splits, making it practical for classification problems with hundreds of categories.
13. Limitations
- Softmax GBM trains K trees per round, making total computation K× that of binary GBM. For K=100 classes this becomes prohibitive with naive implementation; LightGBM’s histogram method mitigates but does not eliminate the cost.
- SAMME does not produce calibrated probability estimates by default — the softmax of the weighted votes is a heuristic approximation, not a theoretically grounded probability. Use CalibratedClassifierCV if calibrated outputs are required.
- One-vs-rest decomposition loses inter-class information: a class-3 sample is treated as a negative example for all eight other classifiers, which distorts the training signal when classes are correlated.
14. Common Failure Modes
- Using algorithm=’SAMME.R’ in sklearn 1.6+. SAMME.R was removed in sklearn 1.7 — only SAMME is now valid. Always check the sklearn version before using the algorithm parameter.
- Setting max_depth too high for large K. With K=10 and max_depth=5, each round fits 10 depth-5 trees — the per-round computational cost is 10× the binary case with deep trees that risk overfitting. Fix: use max_depth=2–3 for K > 5.
- Evaluating with accuracy on imbalanced multi-class data. A 9-class problem where one class has 50% of samples can achieve 50% accuracy by predicting only that class. Always report macro-F1 and per-class metrics alongside accuracy.
- Not stratifying the train-test split on multi-class data. With K=10 and small datasets, some classes may not appear in the test set without stratification, making evaluation metrics undefined. Always use stratify=y.
15. Best Practices
- For K ≤ 10 and accuracy as the primary metric, softmax GBM (GradientBoostingClassifier with loss=’log_loss’) is the default recommendation. It jointly optimises all class predictions and produces calibrated probabilities.
- For very large K (>50 classes), use LightGBM with objective=’multiclass’ and num_class=K — its histogram-based trees make the K-times-per-round computation tractable.
- Report macro-averaged F1 alongside accuracy for any multi-class evaluation. Macro-F1 treats all classes equally regardless of frequency, which is usually the right criterion for multi-class business problems.
- Always use stratify=y in train_test_split and StratifiedKFold for cross-validation on multi-class tasks. Unstratified splits can leave entire classes out of evaluation folds on small datasets.
16. Conclusion
Multi-class boosting requires extending the binary loss function to K classes, either through SAMME’s corrected exponential loss, one-vs-rest decomposition, or native softmax gradient descent. Softmax GBM is the recommended default: it optimises a theoretically sound multi-class cross-entropy loss, produces well-calibrated K-dimensional probabilities, and scales to large K via XGBoost and LightGBM’s efficient implementations. SAMME is the right choice when you need the theoretical guarantees of AdaBoost extended to multi-class settings, or when the base learner does not support probability outputs required by SAMME.R.



