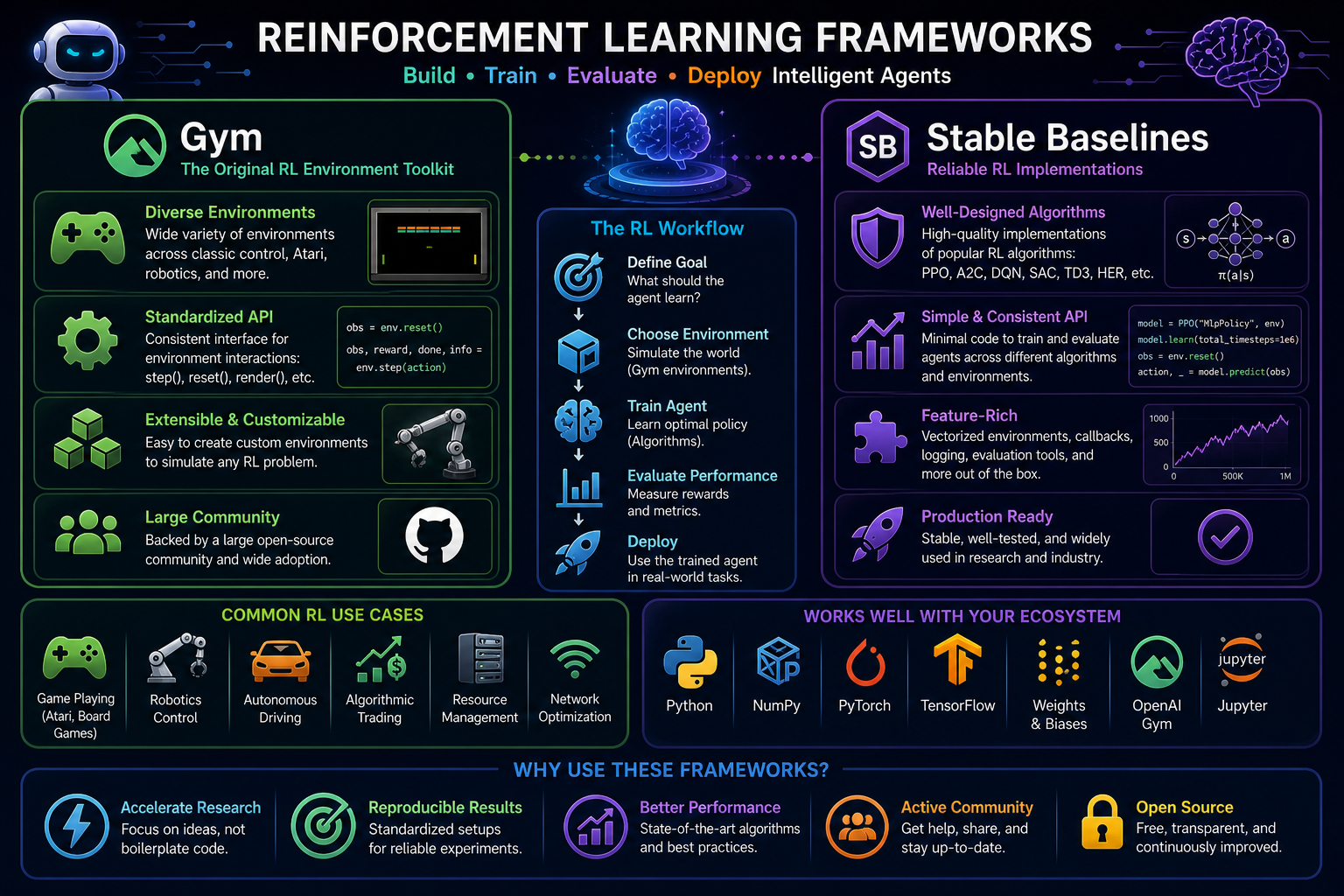
Reinforcement learning frameworks provide the software structure needed to define environments, train agents, evaluate policies, and reproduce experiments in sequential decision-making problems. Among the most influential frameworks in the Python ecosystem are Gym-style environment APIs and the Stable Baselines family of algorithm implementations. Although they are often mentioned together, they solve different layers of the RL stack: Gym standardizes the environment interface, while Stable Baselines provides reusable implementations of RL algorithms.
Abstract
Reinforcement learning differs from supervised learning because agents do not simply map static inputs to labels. Instead, they act in environments, receive rewards, update behavior through experience, and optimize long-term return. This requires a software stack that cleanly separates environments from algorithms. Gym-style APIs define a standard interface through which agents interact with environments using reset and step operations, observation spaces, and action spaces. Stable Baselines and especially Stable-Baselines3 provide reliable implementations of major RL algorithms on top of that environment layer. This paper explains the technical roles of Gym-style APIs and Stable Baselines, the current relationship between legacy OpenAI Gym and the maintained Gymnasium fork, the structure of RL training loops, policy optimization concepts, environment wrappers, evaluation, reproducibility, and practical tool selection. All formulas are embedded inline in HTML-friendly format for direct use in WordPress or similar editors.
1. Introduction
In reinforcement learning, an agent interacts with an environment over time. At time
t, the agent observes a state or observation
st, takes an action
at, receives reward
rt+1, and transitions to
st+1.
The objective is typically to maximize expected discounted return:
Gt = Σk=0∞ γk rt+k+1,
where γ is the discount factor.
RL frameworks are useful because they provide reusable abstractions for the environment-agent interaction loop rather than forcing every project to build that loop from scratch.
2. Why RL Frameworks Matter
RL systems are harder to standardize than ordinary predictive modeling pipelines because they involve:
- stateful interaction over time
- simulation or real-world environment dynamics
- exploration versus exploitation trade-offs
- stochastic transitions and rewards
- episode boundaries and truncation logic
- algorithm-specific training procedures
RL frameworks matter because they make these moving parts modular and comparable.
3. Environment Layer vs Algorithm Layer
A useful distinction is:
- environment framework: defines how the agent communicates with the world
- algorithm framework: defines how the policy or value function is optimized
Gym-style APIs belong mainly to the first category, while Stable Baselines belongs mainly to the second.
4. OpenAI Gym and the Current Landscape
The current maintained environment standard is Gymnasium. The official Gymnasium documentation describes Gymnasium as a maintained fork of OpenAI’s Gym, and its GitHub page says it is where future maintenance will occur going forward. Gymnasium also describes itself as an API standard for reinforcement learning with a diverse collection of reference environments. This matters because when practitioners say “Gym” today, they often mean the legacy API lineage whose maintained path now continues through Gymnasium.
5. Why Gym Was Important
Gym was historically important because it standardized the environment interface for RL research and education. A standard API made it much easier to:
- swap algorithms across environments
- compare results on common benchmarks
- share training code and evaluation logic
- teach RL with a consistent software model
This standardization is one of the major reasons RL experimentation became much more reusable across projects.
6. Gymnasium as the Maintained API Standard
Gymnasium’s documentation describes it as an API standard for single-agent reinforcement learning environments and explains that the interface is simple and pythonic. It also notes a migration path for old Gym environments. In current practice, Gymnasium is therefore the maintained continuation of the Gym-style environment interface.
7. Core Environment Abstraction
A Gym-style environment defines a loop centered on two core methods:
reset()to initialize or reinitialize the environmentstep(a)to apply actionaand return the transition result
Conceptually:
(st+1, rt+1, terminated, truncated, info) = Env.step(at).
8. The Step API Change
Gymnasium’s core API documentation explicitly states that the step API changed by removing
done in favor of separate
terminated
and
truncated
signals. This distinction matters because bootstrapping algorithms need to know whether an episode ended due to
task termination or external truncation, such as a time limit.
9. Observation and Action Spaces
Gym-style APIs also standardize observation and action spaces. If observation space is
𝒮 and action space is 𝒜, then a valid RL environment
enforces:
st ∈ 𝒮
and
at ∈ 𝒜.
This is important because algorithms rely on consistent assumptions about whether actions are discrete, continuous, multi-discrete, or otherwise structured.
10. Reference Environments
Gymnasium provides a standard API together with reference environments. These environments are valuable for:
- algorithm debugging
- benchmarking
- education
- reproducible experimentation
Additional ecosystem projects such as Gymnasium-Robotics extend the same API into more specialized domains.
11. Wrappers and Environment Composition
Gym-style ecosystems make heavy use of wrappers. A wrapper transforms or augments environment behavior while keeping the same external interface. This can be used for:
- observation normalization
- reward shaping
- frame stacking
- action clipping
- episode recording
Wrappers are important because they let users modify behavior without rewriting the environment itself.
12. Stable Baselines and Stable-Baselines3
The current official implementation line is Stable-Baselines3, or SB3. The official SB3 documentation describes it as a set of reliable implementations of reinforcement learning algorithms in PyTorch and explicitly says it is the next major version of Stable Baselines. This is important because the user’s phrase “Stable Baselines” is now most practically realized through SB3 in current usage.
13. Stable Baselines Design Philosophy
Stable Baselines3 is best understood as an algorithm implementation framework. Its main value is not defining the RL environment API, but providing reusable, well-tested, and documented implementations of major RL methods so that users can focus on experiments and environments rather than reimplementing algorithms from scratch.
14. Why Reliable Implementations Matter
RL algorithms can be difficult to implement correctly because they are often sensitive to:
- advantage estimation details
- normalization choices
- target update logic
- rollout collection procedures
- optimizer settings
- termination handling
Reliable reference implementations therefore have substantial practical value, especially for reproducibility and learning.
15. SB3 and PyTorch
The official SB3 docs explicitly state that SB3 is implemented in PyTorch. This matters because it situates SB3 in the modern PyTorch ecosystem and makes it familiar to users already working in PyTorch-based research and engineering workflows.
16. Common Algorithms in Stable-Baselines3
Stable-Baselines3 includes implementations of major RL algorithms. One representative example in the official docs is PPO, or Proximal Policy Optimization. The PPO page explains that PPO combines ideas from A2C and TRPO and uses clipping so the new policy does not move too far from the old one during updates.
A simplified PPO surrogate objective can be written as:
L = E[min(rt(θ)Ât, clip(rt(θ), 1-ε, 1+ε)Ât)],
where:
rt(θ)is the policy ratioÂtis the estimated advantageεis the clipping threshold
17. RL Training Loop with Gym-Style Environments and SB3
A typical training workflow looks like:
- create a Gym/Gymnasium-compatible environment
- instantiate an SB3 algorithm with policy and hyperparameters
- collect rollouts by interacting with the environment
- optimize the policy/value networks from collected experience
- evaluate and save the resulting model
Conceptually:
env → rollout data → update policy → repeat.
18. Policy and Value Function Abstractions
RL algorithms often rely on:
- a policy
π(a|s)that maps states to action probabilities or actions - a value function
V(s)or action-value functionQ(s,a)
Stable Baselines implementations package these components together into practical algorithm classes so users do not need to wire the full training logic manually.
19. Vectorized Environments
RL training often benefits from running multiple environments in parallel. If
n environments are stepped together, rollout collection becomes more sample-efficient
in wall-clock terms because the algorithm gathers more transitions per unit time.
Conceptually, parallel rollout collection can be viewed as:
Collect {(s, a, r, s')} from env1, ..., envn simultaneously.
20. Reproducibility and Benchmarking
Gym-style APIs and Stable Baselines are useful together because they support reproducible experiments across shared benchmarks. When many researchers or engineers use the same environment interface and common algorithm implementations, result comparison becomes much more meaningful.
21. RL Baselines3 Zoo and Ecosystem Extensions
The official SB3 documentation points to RL Baselines3 Zoo as a training framework around SB3, and SB3-Contrib is positioned as a place for experimental algorithms and tools that keep the style of SB3 but are less mature. This shows that the Stable Baselines ecosystem extends beyond only the core package into experiment management and experimental extensions.
22. Gym/Gymnasium vs Stable Baselines: Core Orientation
A practical distinction is:
- Gym/Gymnasium standardizes the environment interface for RL.
- Stable Baselines3 provides reliable implementations of RL algorithms that operate on such environments.
This is one of the most important conceptual distinctions in the RL software stack.
23. Why They Are Complementary
These frameworks are complementary rather than competing. In practice, a common stack is:
- Gymnasium environment API for interaction standardization
- Stable-Baselines3 algorithm for training
- optional wrappers, vectorization, logging, and experiment tools around them
This layered approach makes RL experimentation substantially easier than building both the environment API and algorithm implementations from scratch.
24. Common Use Cases
Gym-style APIs and SB3 are especially useful for:
- RL education and teaching
- benchmarking on classic control and toy environments
- training agents in simulated tasks
- algorithm comparison
- rapid prototyping of RL ideas
- custom environment experimentation
25. Limitations and Practical Boundaries
Gymnasium is an environment standard, not a full RL algorithm platform. Stable-Baselines3 is a reliable algorithm implementation library, but it does not remove the difficulty of reward design, simulator quality, exploration difficulty, or environment realism. These frameworks make RL more usable, but they do not solve the conceptual hardness of RL itself.
26. Common Failure Modes
- confusing the environment API layer with the algorithm implementation layer
- using outdated Gym assumptions without accounting for Gymnasium’s maintained API semantics
- treating benchmark success as proof of real-world policy robustness
- ignoring truncation versus termination semantics in bootstrapping algorithms
- assuming reliable algorithm implementations eliminate the need for reward and environment design care
27. Best Practices
- Use Gymnasium-style APIs for maintained, standardized environment interaction.
- Use Stable-Baselines3 when you need reliable PyTorch implementations of standard RL algorithms.
- Keep environment design, reward shaping, and evaluation logic explicit rather than burying them inside wrappers without documentation.
- Pay close attention to termination and truncation semantics when implementing RL training loops.
- Separate environment benchmarking from real-world performance claims.
28. Conclusion
Reinforcement learning frameworks are most useful when understood as layers of a stack rather than as one monolithic tool. Gym, historically, helped standardize RL environments, and that maintained lineage now continues through Gymnasium. Stable Baselines, in current practice Stable-Baselines3, provides reliable PyTorch implementations of important RL algorithms on top of that environment interface.
The most useful practical lesson is that these tools are complementary. Gym-style APIs make environments reusable and comparable, while Stable Baselines makes algorithms accessible and reproducible. Together they provide a highly practical entry point into reinforcement learning engineering, experimentation, and education.



