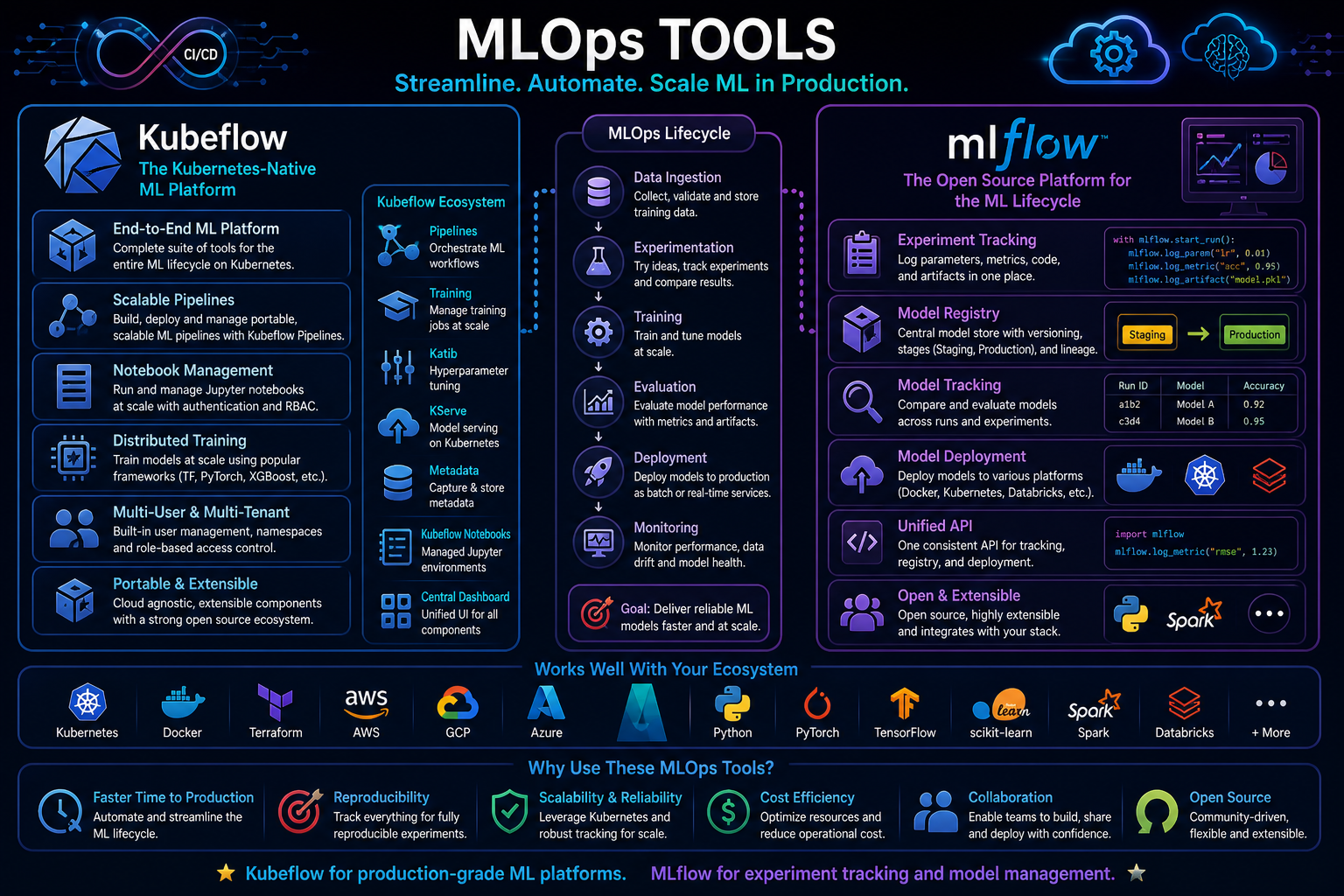
MLOps tools provide the infrastructure, workflows, and governance needed to take machine learning systems from experimentation to reliable production use. They help teams manage repeatability, orchestration, versioning, deployment, monitoring, collaboration, and lifecycle control across models, data, pipelines, and environments. Among the most important tools in this space are Kubeflow and MLflow. Although both are associated with MLOps, they solve different parts of the machine learning operations stack and reflect different architectural philosophies.
Abstract
MLOps is the discipline of operationalizing machine learning through reproducible workflows, automation, governance, and production reliability. In practice, this means teams need systems for experiment tracking, artifact management, pipeline orchestration, metadata lineage, model versioning, scalable training, deployment, monitoring, and collaboration across environments. Kubeflow and MLflow are two widely used open-source tools that address these needs from different starting points. Kubeflow is positioned as a Kubernetes-native foundation of tools for AI platforms and includes modular projects for workflows, notebooks, hyperparameter tuning, model management, and inference integrations. MLflow is positioned as an open-source AI engineering platform supporting the lifecycle of agents, LLMs, and machine learning models, with core capabilities such as experiment tracking, projects, model packaging, registry, evaluation, and observability-oriented workflows. This paper explains the technical roles, abstractions, strengths, limitations, and practical fit of Kubeflow and MLflow, and shows how they can complement each other in real-world MLOps architectures. All formulas are embedded inline in HTML-friendly format for direct use in WordPress or similar editors.
1. Introduction
Let a machine learning lifecycle be represented as:
L = (D, φ, T, E, R, S, O),
where:
Dis data managementφis preprocessing and feature logicTis training and experimentationEis evaluation and validationRis registry, packaging, and release managementSis serving and deploymentOis observability and operational governance
MLOps tools help orchestrate, automate, and standardize one or more parts of L. The
most suitable tool depends on whether the primary need is experiment management, platform orchestration, lifecycle
tracking, Kubernetes-native workflows, or end-to-end operational integration.
2. Why MLOps Tools Matter
Machine learning systems are harder to operationalize than traditional software artifacts because they involve:
- data and label dependency
- stochastic training processes
- model version drift over time
- separate offline and online execution paths
- retraining, revalidation, and promotion workflows
- complex relationships among data, code, metrics, and artifacts
Without dedicated MLOps tooling, these processes become difficult to reproduce, govern, and scale.
3. A General Mathematical View of the MLOps Lifecycle
A trained model can be viewed as:
M = Train(D, φ, λ, C),
where:
Dis the input datasetφis the transformation logicλis the hyperparameter configurationCis the code and environment state
MLOps tools aim to preserve and operationalize this lineage so that the model can be reproduced, evaluated, governed, and deployed consistently.
4. Kubeflow Overview
The current Kubeflow introduction describes Kubeflow as “the foundation of tools for AI Platforms on Kubernetes” and says AI platform teams can use projects independently or deploy the entire AI reference platform. The documentation also describes the Kubeflow AI reference platform as composable, modular, portable, and scalable, and the main docs site organizes Kubeflow around multiple component projects. Kubeflow Pipelines is documented as a platform for building and deploying portable and scalable ML workflows using containers on Kubernetes-based systems.
5. Kubeflow Design Philosophy
Kubeflow is best understood as a Kubernetes-native platform foundation for AI and ML operations. Its design is not centered on one specific artifact type such as experiments or models alone. Instead, it provides a modular environment in which multiple AI platform capabilities can be assembled around Kubernetes-native workflows.
This makes Kubeflow especially relevant for platform teams building internal AI platforms rather than only for individuals managing isolated experiments.
6. Kubeflow’s Modular Project Structure
The Kubeflow documentation explicitly organizes the ecosystem into component projects and add-ons. This modularity is important because it means Kubeflow is not one monolithic tool; it is a foundation composed of interoperable components such as pipelines, notebooks, tuning, model-related services, and inference integrations.
7. Kubeflow Pipelines
Kubeflow Pipelines, or KFP, is documented as a platform for building and deploying portable and scalable machine learning workflows using containers on Kubernetes-based systems. This is a central clue to Kubeflow’s role: it is strongly workflow- and orchestration-oriented. Pipelines allow teams to describe a multi-step ML process as a reproducible directed workflow rather than as ad hoc scripts.
8. Pipelines as Workflow Graphs
A pipeline can be conceptualized as a directed acyclic graph:
P = (V, E),
where:
Vis the set of pipeline steps such as preprocessing, training, evaluation, and deploymentEis the dependency structure between those steps
Kubeflow’s orchestration value lies in reliably executing and tracking such graphs on Kubernetes infrastructure.
9. Notebooks and Interactive Workspaces in Kubeflow
Kubeflow Notebooks is documented as a component with stable status, and the Central Dashboard is documented as an authenticated web interface acting as a hub for Kubeflow and ecosystem components. This shows that Kubeflow is not limited to batch orchestration; it also includes interactive user-facing platform capabilities.
10. Hyperparameter Optimization in Kubeflow
The Kubeflow site highlights Katib as a Kubernetes-native project for automated machine learning with support for hyperparameter tuning, early stopping, and neural architecture search. This reinforces Kubeflow’s role as a platform for operational ML workflows rather than just one narrow lifecycle function.
11. Model Serving and Inference in the Kubeflow Ecosystem
The Kubeflow site highlights KServe as a standardized distributed generative and predictive AI inference platform for scalable multi-framework deployment on Kubernetes, and Kubeflow’s historical materials note the transition from KFServing to KServe. This shows that serving and inference are part of the broader Kubeflow ecosystem, even if they are implemented as modular companion projects rather than one single Kubeflow binary.
12. Strengths of Kubeflow
- Kubernetes-native platform orientation
- modular and composable architecture
- strong workflow orchestration through Kubeflow Pipelines
- fit for internal AI platform teams and multi-component AI stacks
- ecosystem coverage spanning notebooks, tuning, model registry directions, and inference integrations
These strengths are directly supported by the current Kubeflow introduction, docs structure, and component pages.
13. Limitations of Kubeflow
Kubeflow’s platform nature is also a trade-off. Because it is Kubernetes-native and platform-oriented, it is more infrastructure-heavy than lightweight experiment tracking tools. It is especially appropriate where teams need a composable AI platform, but it may be more operationally involved than necessary for smaller teams whose primary need is model lifecycle tracking rather than full workflow platforming. This is an inference from its official positioning as a foundation for AI platforms on Kubernetes.
14. MLflow Overview
MLflow’s official site describes MLflow as “the largest open source AI engineering platform for agents, LLMs, and ML models,” and states that it enables teams to debug, evaluate, monitor, and optimize production-quality AI applications while controlling costs and managing access to models and data. The MLflow docs page still presents core ML capabilities such as experiment tracking, model packaging, registry management, and deployment. The classical ML page describes MLflow as a unified platform for the entire GenAI and ML model lifecycle, and the docs for MLflow Projects, Model Registry, and evaluation describe key lifecycle management capabilities in detail.
15. MLflow Design Philosophy
MLflow is best understood as a lifecycle management and AI engineering platform rather than a Kubernetes-native AI platform foundation. Its core value is helping teams track, package, register, evaluate, and operationalize models and AI applications across environments without forcing one underlying infrastructure model.
This makes MLflow especially attractive when the central need is lifecycle visibility and collaboration around models and runs, rather than full platform orchestration.
16. Experiment Tracking in MLflow
One of MLflow’s foundational roles is experiment tracking. Conceptually, a tracked run can be represented as:
Run = (params, metrics, artifacts, tags).
This matters because reproducibility in ML often depends on preserving the full relationship among parameter settings, code outputs, logged metrics, and resulting artifacts.
17. MLflow Projects
The MLflow Projects documentation describes Projects as a standard format for packaging and sharing reproducible data science code based on simple conventions. This highlights MLflow’s emphasis on reproducibility and portability at the project execution level.
18. Model Registry in MLflow
The MLflow Model Registry is documented as a centralized model store with APIs and UI for collaboratively managing the full lifecycle of a machine learning model. The docs explicitly mention lineage, versioning, aliasing, metadata tagging, and annotation support. This makes registry management one of MLflow’s clearest strengths.
19. Evaluation in MLflow
MLflow documentation also covers evaluation for classical ML as well as separate GenAI-oriented evaluation pathways. This is important because it shows the platform’s current scope extending beyond simple artifact logging into richer quality and observability workflows for both traditional ML and newer AI application classes.
20. MLflow’s Current Broader Scope
MLflow’s current official positioning is notably broader than “experiment tracker for classical ML.” The homepage and core pages explicitly frame it around agents, LLMs, and ML models. Newer official materials also describe AI Gateway as part of the MLflow Tracking Server with a single secure endpoint for multiple LLM providers. This means the current MLflow identity is best seen as an open-source AI engineering platform spanning both traditional and generative AI workloads.
21. Strengths of MLflow
- strong experiment and run lifecycle tracking
- project packaging and reproducibility support
- centralized model registry with lineage and versioning
- broad applicability across classical ML and newer AI application workflows
- framework-neutral and open integration posture
These strengths are directly reflected in the official MLflow documentation and product pages.
22. Limitations of MLflow
MLflow is not primarily a Kubernetes-native orchestration platform like Kubeflow. It can integrate into broader infrastructure and deployment workflows, but its core value is lifecycle tracking and AI engineering coordination rather than acting as a modular AI platform foundation built around Kubernetes-native workflow execution. This is a comparison based on the official positioning of both tools.
23. Kubeflow vs MLflow: Core Orientation
A practical distinction is:
- Kubeflow is a Kubernetes-native foundation of tools for building AI platforms and orchestrating portable ML workflows.
- MLflow is an AI engineering and lifecycle management platform focused on tracking, packaging, evaluation, registry, and operational model/application management.
This is one of the most useful ways to understand the relationship between the two systems.
24. Workflow Orchestration vs Lifecycle Tracking
Kubeflow’s strongest identity is workflow and platform orchestration on Kubernetes. MLflow’s strongest identity is tracking and managing the lifecycle of models and AI runs across environments. This means:
- Kubeflow answers more of the “how do we run and compose ML workflows at platform scale?” question.
- MLflow answers more of the “how do we track, compare, package, version, and govern model/application artifacts?” question.
25. Why They Are Often Complementary
In real-world architectures, Kubeflow and MLflow can complement each other. A common pattern is:
- use Kubeflow Pipelines to orchestrate training and evaluation workflows on Kubernetes
- log runs, metrics, and artifacts into MLflow during those workflows
- register resulting models in MLflow Model Registry
- use Kubeflow ecosystem components for further platform-level deployment or inference integration
This layered architecture works because orchestration and lifecycle management are related but not identical needs.
26. Choosing the Right Tool
A practical selection guide is:
- Choose Kubeflow when you need Kubernetes-native workflow orchestration and a modular AI platform foundation.
- Choose MLflow when you need strong experiment tracking, model registry, project packaging, and lifecycle visibility.
- Use both together when your organization needs both platform orchestration and rigorous lifecycle management.
27. Common Failure Modes
- treating Kubeflow and MLflow as direct substitutes rather than complementary layers
- choosing Kubeflow when the team mainly needs lightweight lifecycle tracking
- choosing MLflow when the organization actually needs Kubernetes-native pipeline orchestration at platform scale
- building workflows without preserving run and artifact lineage
- separating orchestration from registry and governance with no clear integration plan
28. Best Practices
- Choose the tool based on the MLOps layer you actually need to solve.
- Use Kubeflow for composable Kubernetes-native workflow and platform orchestration.
- Use MLflow for experiment tracking, packaging, registry, and lifecycle governance.
- Integrate orchestration and lifecycle tracking rather than treating them as isolated concerns.
- Design MLOps systems around reproducibility, lineage, and operational clarity from the beginning.
29. Conclusion
Kubeflow and MLflow are both important MLOps tools, but they address different centers of gravity in the machine learning operations landscape. Kubeflow provides a Kubernetes-native foundation for building AI platforms and orchestrating modular ML workflows. MLflow provides strong lifecycle tracking, reproducibility, packaging, registry, and increasingly broad AI engineering support across models, LLMs, and agents.
The most useful comparison is therefore not which tool is universally better, but which one better matches the role required in the system. In many mature organizations, the right answer is not one or the other, but both: Kubeflow for platform and workflow execution, and MLflow for experiment and artifact lifecycle management. When used together thoughtfully, they form a strong practical foundation for scalable MLOps.



