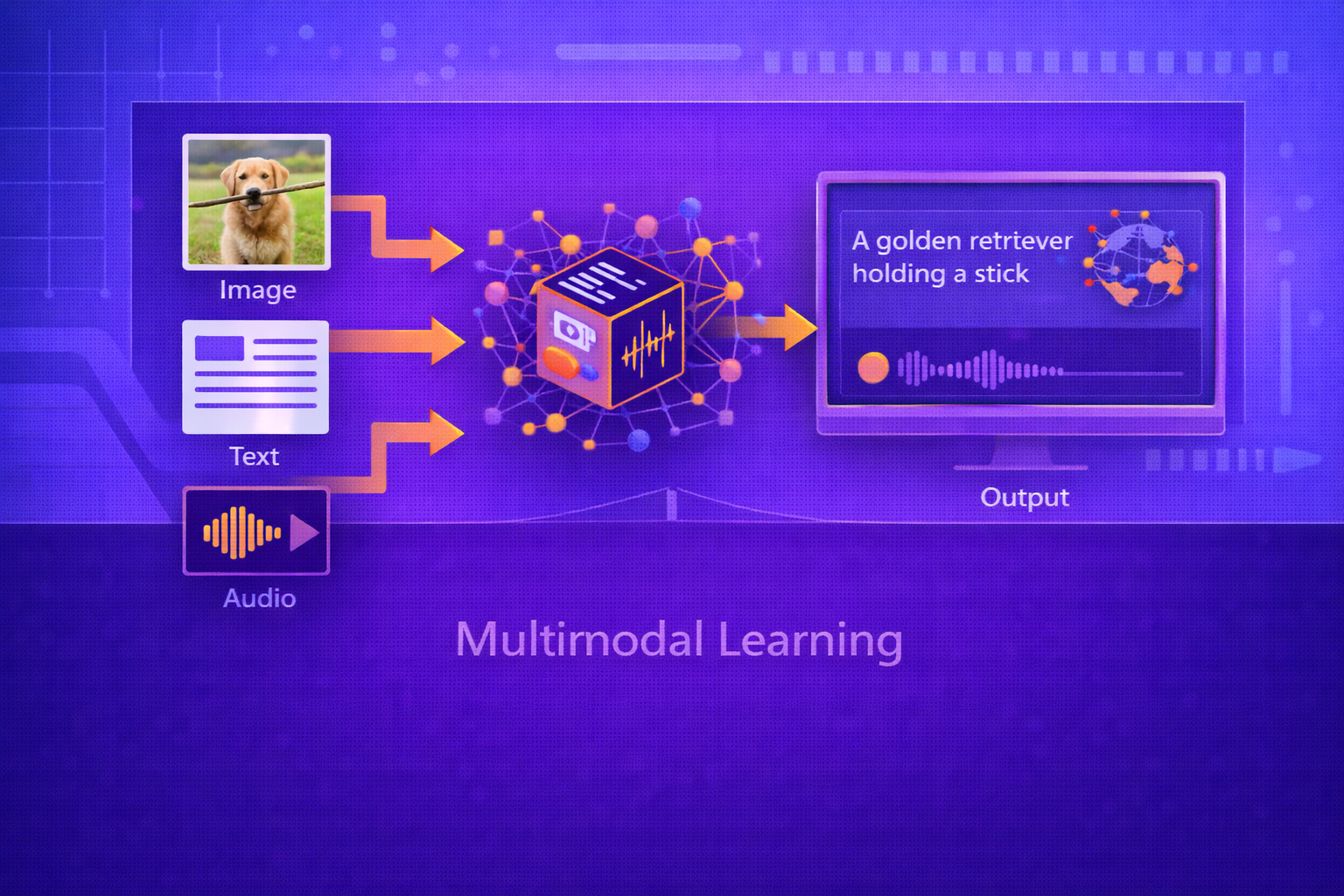
Multimodal Learning is the area of machine learning concerned with building models that can process, align, fuse, reason over, and generate information across multiple data modalities such as text, images, audio, video, graphs, sensor streams, and structured metadata. This whitepaper explains the foundations, architectures, objectives, challenges, and applications of multimodal learning in technical depth.
Abstract
Real-world information is rarely unimodal. Human communication and perception combine language, vision, sound, gesture, context, and memory. Many important machine learning problems likewise involve more than one modality: image captioning combines vision and language, audiovisual speech recognition combines sound and video, medical diagnosis may combine scans with clinical notes, and robotics often integrates vision, proprioception, and action. Multimodal learning seeks to exploit complementary information across modalities to improve representation, prediction, retrieval, and generation. This paper explains multimodal representation learning, fusion mechanisms, alignment, co-attention, contrastive learning, cross-modal retrieval, encoder-decoder generation, multimodal pretraining, and major system challenges such as missing modalities, synchronization, modality imbalance, and grounding. All formulas are embedded inline in HTML-friendly format for direct use in WordPress or similar editors.
1. Introduction
Let a data instance contain multiple modalities:
x = (x(1), x(2), ..., x(M)),
where each x(m) belongs to modality
m. For example:
- text + image
- audio + video
- sensor time series + metadata
- medical images + clinical records
Multimodal learning aims to build a function
f(x(1), ..., x(M))
that captures information within and across modalities more effectively than separate unimodal models.
2. Why Multimodal Learning Matters
Different modalities often provide complementary information. A spoken sentence provides lexical content through audio, but facial movement and video may help disambiguate noisy acoustics. A product image provides visual details, while text provides brand, attributes, or intent. A medical scan may reveal anatomy, while clinical notes add diagnosis context.
Multimodal learning matters because:
- some modalities compensate for weaknesses in others
- joint reasoning can improve accuracy and robustness
- cross-modal retrieval and generation become possible
- many real-world tasks require grounded understanding
3. Modalities and Their Characteristics
Different modalities have different structures:
- Text: discrete symbolic sequences
- Images: spatial grids
- Audio: continuous temporal waveforms or spectrograms
- Video: spatiotemporal sequences
- Tabular metadata: structured feature vectors
- Graphs: relational structures
Multimodal systems must often reconcile different sampling rates, dimensions, noise patterns, and semantic levels.
4. Main Goals of Multimodal Learning
Multimodal learning typically involves one or more of the following goals:
- representation: learn shared or coordinated embeddings
- fusion: combine modalities for downstream prediction
- alignment: map corresponding information across modalities
- translation: convert one modality into another
- generation: generate outputs conditioned on one or more modalities
- retrieval: match instances across modalities
5. Unimodal Encoders as Building Blocks
A standard multimodal pipeline begins with separate encoders for each modality. For modality
m, an encoder produces a representation:
h(m) = Em(x(m)).
Examples include:
- transformers for text
- CNNs or vision transformers for images
- temporal CNNs or transformers for audio
- 3D CNNs or video transformers for video
The main multimodal design question is how to combine or coordinate these modality-specific encodings.
6. Representation Spaces
Multimodal learning may use:
- joint representations: all modalities fused into one shared vector
- shared latent spaces: separate encoders map modalities into a common embedding space
- coordinated spaces: modality embeddings remain distinct but are aligned by objectives
If two modalities are mapped into a shared embedding space, one may write:
ztext = Etext(xtext)
and
zimage = Eimage(ximage),
with training encouraging related pairs to lie close together.
7. Fusion Strategies
Fusion refers to combining modality information. Three broad categories are common:
7.1 Early Fusion
In early fusion, modalities are combined at the input or low-level feature stage. If feature vectors are
h(1) and h(2), a simple early fusion
is:
h = CONCAT(h(1), h(2)).
Early fusion allows cross-modal interaction from the beginning, but it may be hard when modalities are highly heterogeneous or misaligned.
7.2 Late Fusion
In late fusion, each modality is processed independently and predictions are combined near the output. If modality-
specific predictions are ŷ(1) and ŷ(2),
one may combine them as:
ŷ = α ŷ(1) + (1-α) ŷ(2).
Late fusion is simple and modular, but it may fail to capture rich internal cross-modal dependencies.
7.3 Intermediate Fusion
Intermediate fusion combines modalities after some level of unimodal encoding but before final prediction. This is often the most flexible and widely used strategy because it balances modality specialization with cross-modal interaction.
8. Simple Fusion Operators
Common fusion operators include:
- concatenation
- sum or average
- elementwise product
- gated fusion
- attention-based fusion
- bilinear pooling
8.1 Gated Fusion
A gating mechanism may weigh one modality by another:
g = σ(W[h(1); h(2)] + b)
and
h = g ⊙ h(1) + (1-g) ⊙ h(2).
This allows the model to adaptively control how much each modality contributes.
9. Attention and Cross-Modal Interaction
Attention mechanisms are central to modern multimodal learning. If modality A attends to modality B, one may compute:
Attention(QA, KB, VB) = softmax(QAKBT / √d) VB.
Here, queries come from one modality while keys and values come from another. This allows one modality to retrieve relevant information from the other.
9.1 Co-Attention
Co-attention refers to architectures in which two modalities attend to each other, often iteratively or jointly. This is common in vision-language tasks such as visual question answering.
10. Alignment Across Modalities
Alignment means identifying corresponding or semantically related elements across modalities. Examples include:
- matching image regions with words or phrases
- aligning audio frames with text tokens
- aligning video segments with captions
Alignment may be explicit, with supervised correspondence labels, or implicit, emerging from training objectives.
11. Contrastive Multimodal Learning
A highly influential modern approach is contrastive representation learning. Given paired examples such as image-text pairs, the goal is to bring matching pairs close in embedding space and push mismatched pairs apart.
Let
zi(img)
and
zi(txt)
be the embeddings for a matched image-text pair. Similarity may be computed as:
sim(i,j) = (zi(img) · zj(txt)) / (||zi(img)|| ||zj(txt)||).
11.1 Contrastive Objective
A common batch-wise contrastive loss resembles InfoNCE:
L = - Σi=1N log [ exp(sim(i,i)/τ) / Σj=1N exp(sim(i,j)/τ) ],
where τ is a temperature parameter.
This encourages matched pairs to have higher similarity than mismatched pairs.
12. Cross-Modal Retrieval
Cross-modal retrieval aims to retrieve one modality given another, such as:
- retrieve images from a text query
- retrieve captions from an image
- retrieve video clips from language descriptions
Shared embedding spaces learned through contrastive or metric learning objectives are especially effective for this.
13. Multimodal Classification
In multimodal classification, the fused representation is used to predict a target label:
ŷ = softmax(W h + b),
where h is a multimodal embedding.
The standard classification loss is cross-entropy:
L = - Σk=1K yk log ŷk.
Examples include audiovisual event classification, multimodal sentiment analysis, and medical diagnosis prediction.
14. Multimodal Generation
Generation tasks produce one modality conditioned on another or several others. Examples include:
- image captioning: generate text from images
- text-to-image generation
- speech-driven video generation
- video summarization with language output
A conditional generative objective may be written as:
P(y | x(1), ..., x(M)).
In autoregressive form:
P(y1:T | x) = Πt=1T P(yt | y<t, x).
15. Vision-Language Models
One of the most prominent multimodal areas is vision-language learning. Typical tasks include:
- image captioning
- visual question answering
- image-text retrieval
- grounded instruction following
These systems often combine visual encoders with text transformers and use alignment, fusion, and generation objectives.
16. Audio-Visual Learning
Audio-visual learning combines sound and visual information. This is useful for:
- speech enhancement
- lip reading
- speaker localization
- event recognition in videos
A key challenge here is temporal synchronization because the audio and video streams must often be aligned at fine timescales.
17. Missing-Modality Robustness
Real systems often face missing modalities at inference time. For example, text metadata may be absent, an image may be corrupted, or a sensor may fail. Robust multimodal systems should degrade gracefully rather than fail completely.
Strategies include:
- modality dropout during training
- imputation or latent completion
- gated reliability weighting
- mixture-of-experts routing
18. Modality Imbalance
Some modalities may dominate learning because they are richer, cleaner, or easier to optimize. For example, text may overpower weak sensor features, or a strong visual signal may overshadow metadata. Effective multimodal learning must avoid collapsing into single-modality dependence when complementary information is actually valuable.
19. Synchronization and Temporal Alignment
In time-dependent multimodal systems, observations must often be aligned:
(xt(audio), xt(video), xt(sensor)).
Misalignment can severely harm fusion and reasoning. This is why temporal models often incorporate cross-modal synchronization mechanisms, alignment losses, or timestamp-aware architectures.
20. Multimodal Transformers
Transformers have become a standard architecture for multimodal learning because they support flexible attention across sequences, patches, and modality tokens. A multimodal transformer may treat features from each modality as a token sequence and allow self-attention or cross-attention across the combined set.
This allows the model to learn both intra-modal structure and inter-modal relationships.
21. Multimodal Pretraining
Large-scale multimodal pretraining often combines objectives such as:
- contrastive alignment
- masked token or patch modeling
- cross-modal matching
- caption generation
- reconstruction of missing modalities
Pretraining on large paired or loosely paired datasets can produce reusable multimodal representations that transfer effectively to downstream tasks.
22. Common Objective Families
22.1 Contrastive Objectives
Encourage paired examples to align in embedding space.
22.2 Matching Objectives
Predict whether two modality instances correspond, e.g.:
ŷ = σ(W h + b).
22.3 Reconstruction Objectives
Predict missing modality content from observed modalities:
L = ||x(m) - \hat{x}(m)||
or a task-appropriate likelihood objective.
22.4 Generative Objectives
Model conditional sequence or signal generation given multimodal context.
23. Evaluation Metrics
Multimodal learning is evaluated differently depending on the task:
- classification metrics such as accuracy, precision, recall, and F1
- retrieval metrics such as Recall@K and mean reciprocal rank
- generation metrics such as BLEU, ROUGE, CIDEr, or semantic similarity
- alignment metrics and grounding-specific evaluations
For retrieval, Recall@K measures whether the correct match appears among the top
K retrieved items.
24. Applications of Multimodal Learning
Multimodal learning is used in:
- image captioning and visual question answering
- text-to-image and image-to-text systems
- autonomous driving with cameras, lidar, radar, and maps
- medical diagnosis combining scans, notes, and lab data
- human-computer interaction with speech, gaze, gesture, and language
- multimedia search and recommendation
- robotics and embodied AI
25. Challenges in Multimodal Learning
Key challenges include:
- heterogeneous representation scales
- cross-modal alignment difficulty
- missing or noisy modalities
- data imbalance across modalities
- high computational cost
- weak supervision for grounding
- evaluation complexity across multiple output types
26. Grounding and Semantics
A core promise of multimodal learning is grounding: connecting abstract symbols such as words to perceptual evidence such as objects, sounds, or actions. Grounding is important because it helps models move beyond purely textual correlations toward more situated understanding.
27. Robustness and Failure Modes
Multimodal systems may fail by:
- over-relying on one modality
- hallucinating unsupported associations across modalities
- failing under missing-modality conditions
- misaligning semantically corresponding information
- being vulnerable to adversarial or spurious cross-modal cues
28. Strengths of Multimodal Learning
- captures complementary information across data types
- enables grounded representation learning
- supports retrieval and generation across modalities
- often improves robustness and task performance
- better matches real-world perception and communication settings
29. Limitations
- requires carefully aligned or paired data in many settings
- can be computationally expensive
- designing effective fusion is nontrivial
- missing or low-quality modalities can degrade performance
- evaluation is often harder than in unimodal tasks
30. Best Practices
- Choose fusion depth according to the task and modality structure.
- Use strong unimodal encoders before focusing on cross-modal fusion.
- Train for missing-modality robustness when deployment conditions are uncertain.
- Use contrastive alignment objectives when retrieval or shared embedding spaces matter.
- Validate whether each modality truly contributes rather than assuming multimodality always helps.
- Monitor modality imbalance and shortcut learning during evaluation.
31. Conclusion
Multimodal learning extends machine learning beyond single data types and toward the richer structure of real-world information. By jointly modeling text, images, audio, video, and other sources, multimodal systems can learn more grounded, flexible, and capable representations than unimodal systems alone.
At the same time, multimodal learning is fundamentally challenging because modalities differ in structure, timing, semantics, and reliability. Effective systems must align, fuse, and reason across these differences without collapsing into shortcut dependence on the easiest modality. Understanding multimodal learning therefore requires understanding both representation learning within each modality and the cross-modal mechanisms that allow these representations to interact meaningfully.