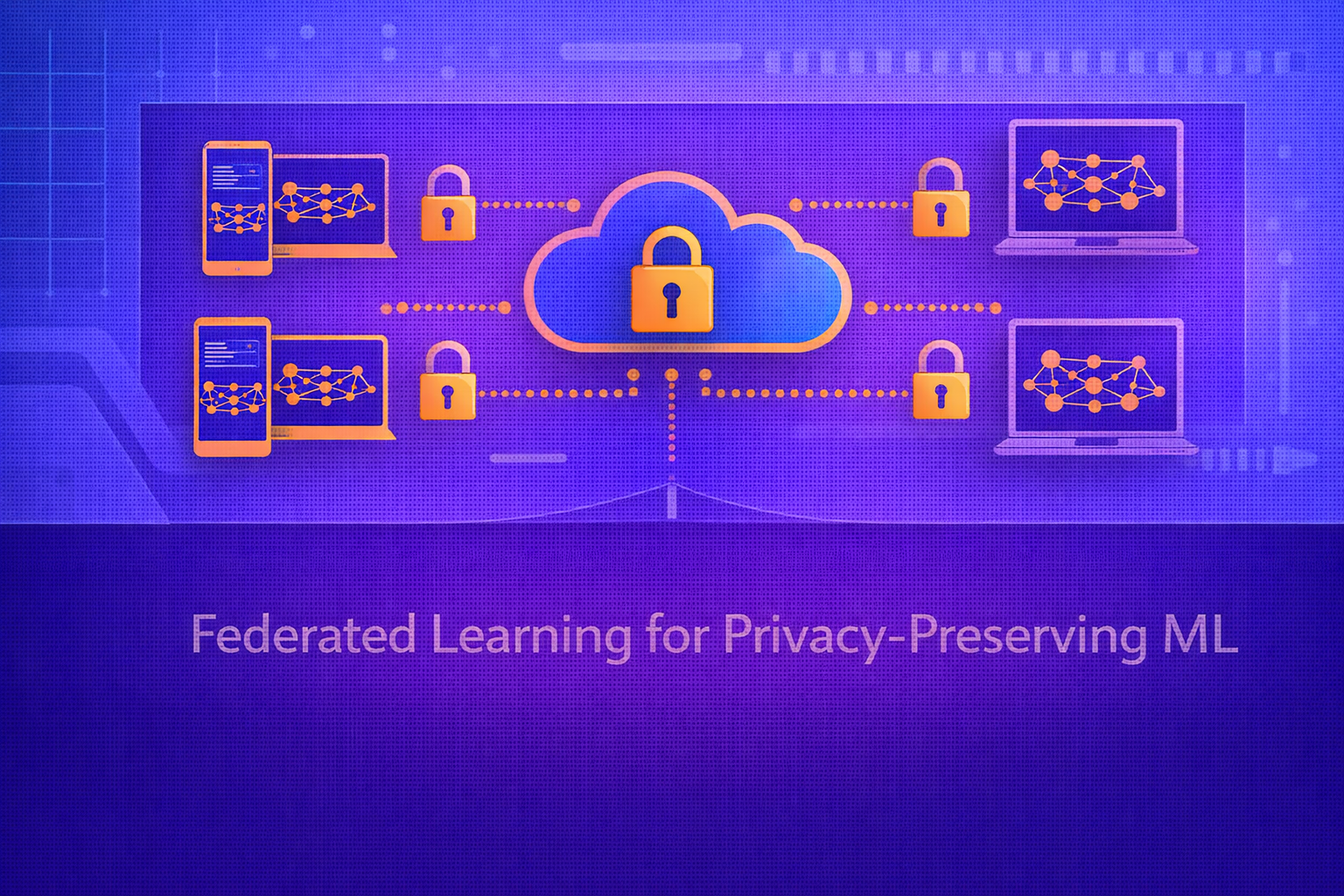
Federated Learning (FL) is a distributed machine learning paradigm in which models are trained collaboratively across many clients or devices without centralizing raw training data. Instead of sending data to the model, federated learning sends the model to the data, then aggregates local updates into a shared global model. This whitepaper explains the foundations, mathematical formulation, privacy implications, system design, optimization challenges, and major algorithmic variants of federated learning for privacy-preserving machine learning.
Abstract
Centralized machine learning traditionally requires collecting data from multiple users, institutions, or devices into a single repository for model training. This raises major concerns around privacy, legal compliance, trust, communication cost, and data governance. Federated Learning addresses this by enabling decentralized training in which participating clients compute updates locally and only model parameters or gradients are shared with a central server or coordination mechanism. While this reduces direct raw-data exposure, it also introduces statistical, optimization, and systems challenges such as non-IID data, device heterogeneity, communication bottlenecks, client dropout, and vulnerability to inference or poisoning attacks. This paper presents a detailed technical treatment of federated learning, including Federated Averaging (FedAvg), optimization objectives, privacy-enhancing techniques such as secure aggregation and differential privacy, cross-device and cross-silo settings, personalization, and practical deployment trade-offs. All formulas are embedded inline in HTML-friendly format for direct use in WordPress or similar editors.
1. Introduction
Machine learning systems often rely on data generated by distributed sources such as mobile phones, hospitals, enterprises, financial institutions, IoT devices, or edge sensors. In many cases, centralizing this data is undesirable or infeasible because of:
- privacy requirements
- regulatory constraints
- data ownership concerns
- bandwidth limitations
- operational trust boundaries
Federated Learning is designed to train models under these constraints by keeping data local while still enabling collaborative model improvement.
2. Core Idea of Federated Learning
In centralized learning, the training dataset is typically:
D = ⋃k=1K Dk,
where Dk is the local dataset owned by client
k.
Centralized training would move all local datasets into one place. Federated learning instead keeps
Dk on client k and only exchanges model
information.
A coordinating server distributes the current global model, clients perform local training, and their updates are aggregated to form a new global model.
3. Federated Learning Objective
Suppose the global model parameters are w. The overall federated objective can be
written as:
minw F(w) = Σk=1K pk Fk(w),
where:
Kis the number of clientsFk(w)is the local objective on clientkpkis the weight of clientk, often proportional to local data size
A common local objective is:
Fk(w) = (1 / nk) Σi=1nk ℓ(w; xi(k), yi(k)),
where nk is the number of examples on client
k.
If weighting is proportional to local dataset size, then:
pk = nk / Σj=1K nj.
4. Local Data Stays Local
The defining operational principle of FL is that raw examples
(x, y) remain on the client side. Only model parameters, gradients, or compressed
update information are transmitted. This reduces direct exposure of private data, although it does not make privacy
absolute, because updates themselves may still leak information if not protected.
5. Federated Learning Workflow
A standard federated training round proceeds as follows:
- the server broadcasts global model parameters
wtto selected clients - each selected client performs local optimization on its private dataset
- each client returns an update or new local model
wt+1(k) - the server aggregates client updates into a new global model
wt+1
This process repeats over many communication rounds.
6. Federated Averaging (FedAvg)
The most influential baseline algorithm in FL is Federated Averaging, or FedAvg. In round
t, the server sends wt to a subset of clients.
Each client performs local SGD for one or more epochs and returns updated parameters
wt+1(k).
The server then computes a weighted average:
wt+1 = Σk ∈ St (nk / nSt) wt+1(k),
where:
Stis the set of participating clients in roundtnSt = Σk ∈ St nk
6.1 Local SGD in FedAvg
On client k, local SGD updates may be:
w := w - η ∇Fk(w; B),
where B is a local minibatch and η is the learning rate.
Multiple local steps reduce communication frequency but increase local drift when client distributions are different.
7. Privacy Motivation vs Privacy Guarantee
Federated learning is often described as privacy-preserving because raw data is not centralized. However, this does not automatically imply formal privacy guarantees. Model updates may still reveal information about local data through gradient inversion, membership inference, or other attacks.
Therefore, FL should be understood as a privacy-enhancing architecture, not a complete privacy solution by itself.
8. Cross-Device vs Cross-Silo Federated Learning
8.1 Cross-Device FL
Cross-device federated learning involves a very large number of clients, such as phones or edge devices. Each client may have limited compute, storage, battery, and intermittent connectivity. Participation is often sparse and stochastic.
8.2 Cross-Silo FL
Cross-silo federated learning involves a smaller number of more stable organizations, such as hospitals, banks, or enterprises. These clients typically have stronger infrastructure, more reliable participation, and larger local datasets.
The statistical and systems assumptions differ substantially between these two settings.
9. Statistical Heterogeneity
One of the defining challenges in FL is that client data is often non-IID. This means local distributions differ:
Pk(x,y) ≠ Pj(x,y)
for different clients k and j.
Heterogeneity can arise from user behavior, geography, demographics, device type, institution-specific populations, or local operational patterns.
Non-IID data makes optimization harder because local steps may push the model in conflicting directions.
10. Systems Heterogeneity
Clients in federated systems often differ in:
- compute speed
- memory capacity
- network bandwidth
- power availability
- uptime and reliability
This affects how many local updates can be performed, which clients can participate, and how aggregation protocols are scheduled.
11. Communication Efficiency
Communication is often the primary bottleneck in federated learning. If the model has
d parameters and many clients participate across many rounds, the communication cost can
be substantial.
FL therefore often uses:
- multiple local steps per round
- model compression
- sparse updates
- quantization
- partial parameter updates
12. Client Sampling
In many federated systems, only a subset of clients participates in each round. If
St is the selected subset at round
t, the aggregation uses only those clients.
Client sampling reduces system load and communication cost, but it also increases stochasticity and may affect fairness if some clients are underrepresented.
13. Secure Aggregation
Secure aggregation is a cryptographic protocol designed so that the server can recover only the aggregate of client
updates, not individual updates. If each client submits update uk, the
server should learn:
Σk uk
without learning each uk separately.
This helps reduce privacy risk from central visibility into individual client updates.
14. Differential Privacy in Federated Learning
Differential privacy (DP) provides a formal privacy guarantee by ensuring that the inclusion or exclusion of a single record has limited impact on the released output. In federated settings, DP can be applied by clipping client updates and adding noise.
A simplified noisy aggregation form is:
ũ = (1/|S|) Σk ∈ S clip(uk, C) + 𝒩(0, σ2I),
where:
clip(uk, C)bounds update norm by thresholdC𝒩(0, σ2I)is Gaussian noise
This improves privacy but often reduces model utility, creating a privacy-utility trade-off.
15. Threat Models in Federated Learning
Federated learning must be analyzed under explicit threat models. Risks include:
- honest-but-curious server: server follows protocol but tries to infer private information
- malicious clients: clients send poisoned or adversarial updates
- eavesdroppers: attackers observe communication channels
- colluding participants: multiple parties try to reconstruct others’ data
16. Gradient Leakage and Inference Attacks
Even if raw data never leaves the client, gradients may encode information about training examples. In some cases, attackers can approximately reconstruct inputs or infer whether certain records were present in local training data.
This is why practical FL deployments often combine architectural decentralization with secure aggregation, differential privacy, and access controls.
17. Poisoning and Byzantine Attacks
Malicious clients may attempt to manipulate the global model by sending poisoned updates. This may aim to:
- degrade overall accuracy
- insert backdoors
- bias the model toward specific outcomes
Byzantine-robust aggregation methods attempt to reduce the effect of adversarial or anomalous updates.
18. Personalized Federated Learning
A single global model may not perform well for all clients when local data distributions differ substantially. Personalized federated learning aims to learn client-specific adaptations.
One conceptual formulation is:
min{wk} Σk=1K [Fk(wk) + λ ||wk - w̄||22],
where:
wkis the client-specific modelw̄is a shared global anchorλcontrols how tightly clients stay aligned
This balances local specialization against shared knowledge.
19. Federated Optimization Challenges
FL is not simply distributed SGD. Compared with centralized optimization, it introduces:
- partial participation
- non-IID client distributions
- multiple local updates between synchronizations
- communication constraints
- client drift
These factors can slow convergence or degrade the quality of the global model if not handled carefully.
20. FedAvg Client Drift
In FedAvg, each client may run several local SGD steps before communicating. If local objectives differ strongly,
the locally updated models may drift away from the direction that best minimizes the global objective
F(w).
This is one reason why non-IID federated optimization is more difficult than centralized minibatch optimization.
21. Federated Proximal Methods
Some methods, such as FedProx, modify the local objective by adding a proximal term:
Fkprox(w) = Fk(w) + (μ/2) ||w - wt||22.
Here, wt is the current global model and
μ penalizes large local deviation. This helps control client drift under heterogeneity.
22. Compression and Quantization
To reduce communication cost, client updates may be compressed. Common strategies include:
- low-bit quantization
- sparse gradient transmission
- top-k coordinate selection
- sketching or low-rank approximations
These reduce bandwidth but may introduce approximation error.
23. Asynchronous Federated Learning
In synchronous FL, the server waits for selected clients before aggregation. In asynchronous FL, updates may be incorporated as they arrive. This reduces waiting for stragglers but introduces staleness because some updates are computed using older model versions.
24. Fairness in Federated Learning
Because clients may vary widely in data size, quality, and participation frequency, optimizing only average global performance may disadvantage smaller or less represented clients. Federated learning therefore raises fairness questions such as:
- whose performance is being optimized
- whether rare client populations are underfit
- how client weighting should be defined
25. Evaluation in Federated Learning
Federated models are often evaluated using standard supervised metrics such as:
Accuracy = (TP + TN)/(TP + TN + FP + FN),
Precision = TP/(TP + FP),
Recall = TP/(TP + FN),
F1 = 2(Precision × Recall)/(Precision + Recall),
or regression metrics such as RMSE.
However, FL also requires system-level evaluation:
- communication rounds
- bandwidth usage
- client participation rate
- robustness to dropout
- privacy leakage risk
- fairness across clients
26. Practical Applications
Federated learning is used or explored in:
- mobile keyboard prediction
- healthcare collaboration across hospitals
- fraud detection across institutions
- IoT and edge intelligence
- personalization on consumer devices
- industrial sensor networks
- multi-organization secure analytics
27. Strengths of Federated Learning
- reduces need to centralize raw data
- aligns with privacy and governance constraints
- supports learning from distributed data silos
- can leverage edge-generated data at scale
- enables collaborative modeling across trust boundaries
28. Limitations of Federated Learning
- does not guarantee privacy by itself
- non-IID data makes optimization difficult
- communication can dominate cost
- client devices may be unreliable or resource-constrained
- susceptible to update leakage and poisoning without additional protection
29. Best Practices
- Use federated learning when raw-data centralization is undesirable or infeasible.
- Combine FL with secure aggregation and, when needed, differential privacy.
- Design for both statistical and systems heterogeneity from the start.
- Monitor fairness and client-level performance, not just global averages.
- Use communication-efficient strategies when bandwidth is limited.
- Harden the aggregation pipeline against poisoning and inference attacks.
30. Conclusion
Federated Learning reframes machine learning training around a simple but powerful idea: collaborative optimization without centralizing raw data. By moving model computation to distributed clients and aggregating updates centrally, FL supports privacy-aware and governance-sensitive machine learning across devices and organizations.
At the same time, federated learning is not a free replacement for centralized training. It introduces difficult challenges in optimization, systems design, privacy protection, communication efficiency, fairness, and security. Understanding FL therefore requires understanding both its promise and its limitations. When combined with secure aggregation, differential privacy, robust optimization, and careful system engineering, federated learning becomes a central framework for privacy-preserving machine learning in modern distributed environments.