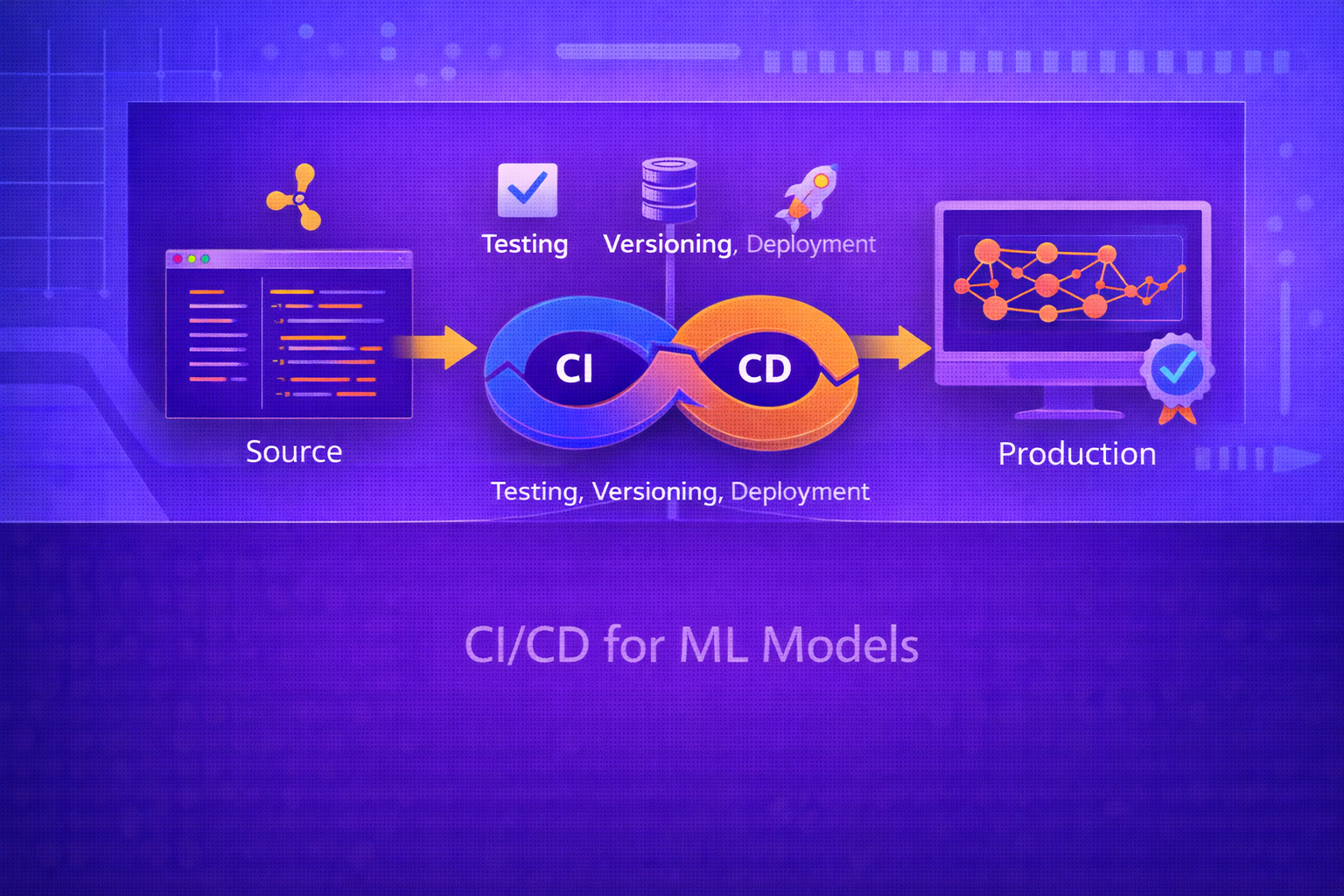
Continuous Integration and Continuous Delivery/Deployment (CI/CD) for machine learning extends software delivery practices into a domain where outputs depend not only on code, but also on data, features, and model behavior over time. In ML systems, CI/CD must validate not only that code builds and tests successfully, but also that data contracts hold, training pipelines remain reproducible, model quality meets thresholds, deployment risk is controlled, and post-release monitoring can detect drift and degradation.
Abstract
Traditional CI/CD pipelines focus on application code, unit tests, packaging, and release automation. Machine learning introduces additional moving parts such as versioned datasets, feature pipelines, training orchestration, experiment tracking, model registries, evaluation metrics, shadow deployments, canary rollouts, and data drift monitoring. As a result, CI/CD for ML is more accurately understood as a broader MLOps discipline that must support both software engineering rigor and statistical validation. This paper explains the structure of CI/CD for ML systems, including source control triggers, validation stages, data and feature checks, training and retraining workflows, artifact packaging, deployment patterns, model promotion gates, online serving integration, rollback, and monitoring. All formulas are embedded inline in HTML-friendly format for direct use in WordPress or similar editors.
1. Introduction
In classical software delivery, Continuous Integration ensures that code changes are merged and tested frequently, while Continuous Delivery or Continuous Deployment ensures that validated artifacts can be released reliably.
In ML, however, the deployed artifact is not just code. A model artifact depends on:
M = Train(D, φ, λ, C, E, s),
where:
Dis the dataset versionφis the feature processing logicλis the hyperparameter configurationCis the code versionEis the runtime environmentsis the seed or stochastic state
Therefore, CI/CD for ML must validate far more than source code correctness alone.
2. Why CI/CD Is Different for ML
ML delivery differs from standard software delivery because:
- data changes can change behavior even when code does not
- training is stochastic and expensive
- success depends on model quality metrics, not just functional correctness
- production conditions can drift away from training conditions
- rollback may require reverting both infrastructure and model versions
As a result, CI/CD in ML combines software engineering, data engineering, evaluation science, and operations.
3. CI/CD vs CT in MLOps
In mature MLOps, one often distinguishes:
- CI: test and validate code, data interfaces, and pipeline changes
- CD: package and deploy serving or pipeline artifacts
- CT: Continuous Training, where models are retrained automatically or semi-automatically when triggered
Continuous Training becomes important because a model may need refresh not only due to code changes, but due to data drift, label accumulation, or business changes.
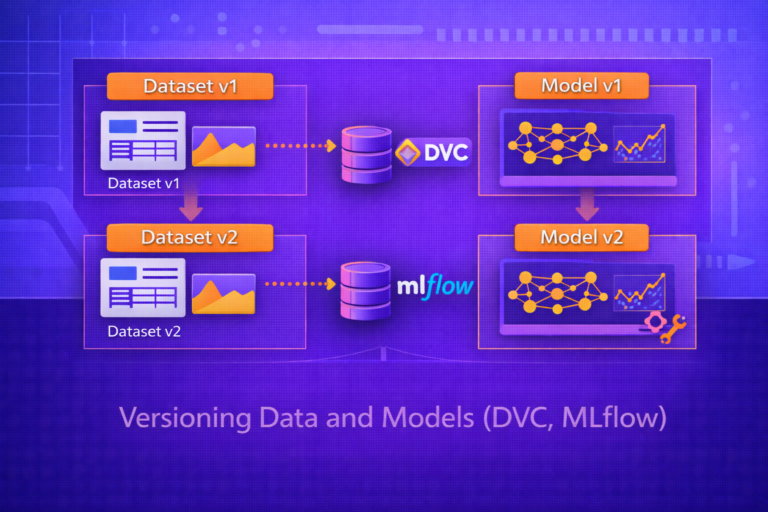
4. Core Artifacts in ML CI/CD
A robust ML CI/CD system manages multiple artifact types:
- source code
- training and inference pipeline definitions
- feature transformation logic
- data version references
- trained model artifacts
- evaluation reports
- container images
- deployment manifests
The release unit may therefore be a tuple such as:
R = (code, image, model, config, metrics, lineage).
5. Continuous Integration for ML
Continuous Integration in ML begins when changes are committed to source control or otherwise introduced into the pipeline. Changes may involve:
- training code
- inference service code
- feature engineering logic
- data schema definitions
- pipeline orchestration definitions
- model configuration files
The CI pipeline should validate that these changes do not break downstream reproducibility, correctness, or system assumptions.
6. Code Validation in ML CI
Standard CI checks still apply in ML systems, including:
- linting
- formatting
- unit tests
- integration tests
- dependency resolution checks
- container build tests
However, they are not sufficient on their own. CI must also test the ML-specific pipeline logic.
7. Data Validation in CI
Because ML systems are data-dependent, CI should validate assumptions about the shape and semantics of data.
If the expected schema is:
S = {(name1, type1), ..., (namem, typem)},
then incoming or reference datasets must be checked against this schema.
Typical CI data checks include:
- required columns present
- types valid
- null rates below thresholds
- categorical values in expected domains
- row count anomalies
- distribution warnings
8. Feature Pipeline Validation
Feature logic must behave consistently across training and inference. If feature transformation is
z = φ(x), then CI should validate:
- the transformation runs successfully on representative samples
- schema of
zremains compatible - statistics are fit only on training data when appropriate
- serialization and deserialization work correctly
This prevents training-serving skew and silent feature breakage.
9. Reproducibility Checks
CI in ML often includes reproducibility validation. If a reference run is defined by:
(D, φ, λ, C, E, s),
then rerunning on the same specification should produce identical or tolerably equivalent outputs.
This matters because non-reproducible pipelines are difficult to debug, audit, or trust.
10. Smoke Training Runs
Full training may be too expensive for every CI event, especially for deep learning. A common strategy is to run reduced smoke tests using:
- small sample datasets
- few epochs or iterations
- reduced model sizes
- synthetic fixtures
These runs do not validate full production quality, but they verify that the pipeline still executes end-to-end.
11. Continuous Training Triggers
Retraining can be triggered by different events:
- code or pipeline changes
- new labeled data arrival
- scheduled retraining cadence
- drift threshold breach
- manual review or business event
If drift score is denoted by Δ, one may retrain when:
Δ > τ,
where τ is a predefined threshold.
12. Training as a Pipeline Stage
In ML CI/CD, training is often formalized as a pipeline stage rather than an ad hoc notebook action. A training run
may be represented as:
Run = Train(Dv, φv, λ, Cv, Ev).
This allows the resulting model to be associated with exact lineage:
- code commit
- data version
- feature pipeline version
- environment build
- evaluation metrics
13. Experiment Tracking in CI/CD
Experiment tracking systems record:
- parameters
- metrics
- artifacts
- tags and lineage references
If run r produces metric vector
m(r), then model promotion logic may choose:
r* = argmaxr Utility(m(r)),
subject to deployment constraints.
14. Model Evaluation Gates
Unlike standard software artifacts, ML artifacts must satisfy statistical quality gates before promotion. Common deployment gates include:
- minimum validation accuracy or F1
- regression error threshold
- fairness checks
- latency constraints
- calibration or robustness checks
- no degradation relative to baseline or production model
If the current production model score is
Sprod and a candidate score is
Scand, a promotion rule may require:
Scand ≥ Sprod + δ.
15. Offline Metrics
Offline evaluation often uses standard supervised metrics.
15.1 Classification
Common metrics include:
Accuracy = (TP + TN)/(TP + TN + FP + FN),
Precision = TP/(TP + FP),
Recall = TP/(TP + FN),
and
F1 = 2(Precision × Recall)/(Precision + Recall).
15.2 Regression
Common metrics include:
MAE = (1/n) Σ |yi - \hat{y}i|
and
RMSE = √[(1/n) Σ (yi - \hat{y}i)2].
16. Beyond Offline Metrics
Offline metrics alone may not capture production performance. CI/CD systems should also consider:
- latency and throughput
- memory footprint
- fairness by subgroup
- robustness under perturbation
- business KPI alignment
- calibration and confidence quality
This is especially important when promoting models to production automatically.
17. Packaging the ML Artifact
Once a model passes validation, it must be packaged for deployment. A packaged artifact may include:
- model weights or serialized object
- preprocessing logic
- postprocessing logic
- environment specification
- input/output signature
- metadata and lineage references
One may conceptualize the deployable unit as:
P = (M, φ, ψ, E, signature, metadata),
where ψ represents postprocessing.
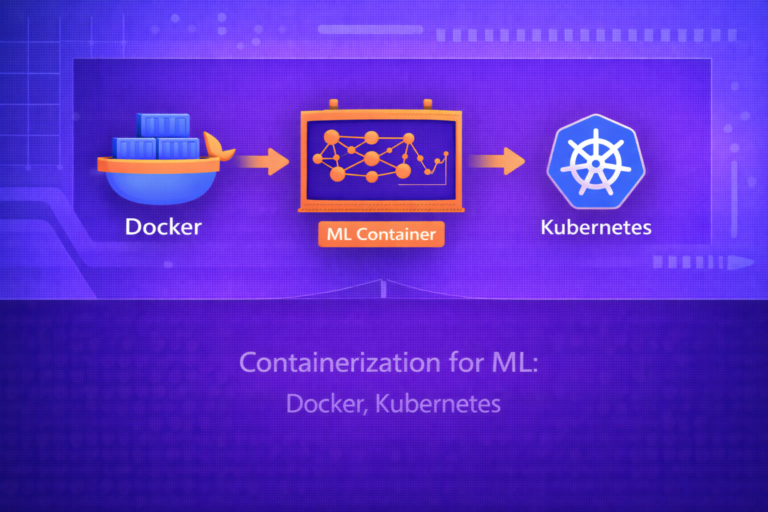
18. Containerization in CD
ML deployment artifacts are frequently containerized. A container image can package:
- inference service code
- runtime dependencies
- model loader logic
- configuration defaults
This improves consistency across environments and makes CD pipelines more reliable.
19. Model Registry and Promotion
A model registry is often the control point for moving models through lifecycle stages such as:
- candidate
- staging
- production
- archived
Promotion should be tied to evaluation evidence, lineage, and possibly manual approval for high-stakes systems.
20. Continuous Delivery vs Continuous Deployment in ML
In Continuous Delivery, validated models are always deployable, but release to production may still require human approval. In Continuous Deployment, promotion to production is fully automated after passing all gates.
Many ML teams prefer Continuous Delivery over full Continuous Deployment because model release decisions often require risk review and business context.
21. Deployment Strategies
Common deployment patterns for ML models include:
- Blue-green deployment: switch traffic from old environment to new one
- Canary deployment: send a small percentage of traffic to the new model
- Shadow deployment: run the new model in parallel without affecting live decisions
- A/B testing: compare variants under controlled traffic allocation
22. Canary Validation
In canary rollout, if traffic fraction sent to the new model is
p, then only that portion of requests is exposed initially:
Trafficnew = p · Traffictotal.
Operational metrics are observed before increasing p toward full rollout.
23. Shadow Mode
Shadow deployment is particularly useful in ML. The new model receives real production inputs but its outputs do not drive decisions. This allows comparison of:
- latency
- prediction distributions
- feature compatibility
- operational stability
Shadow mode is valuable when labels are delayed or rollout risk is high.
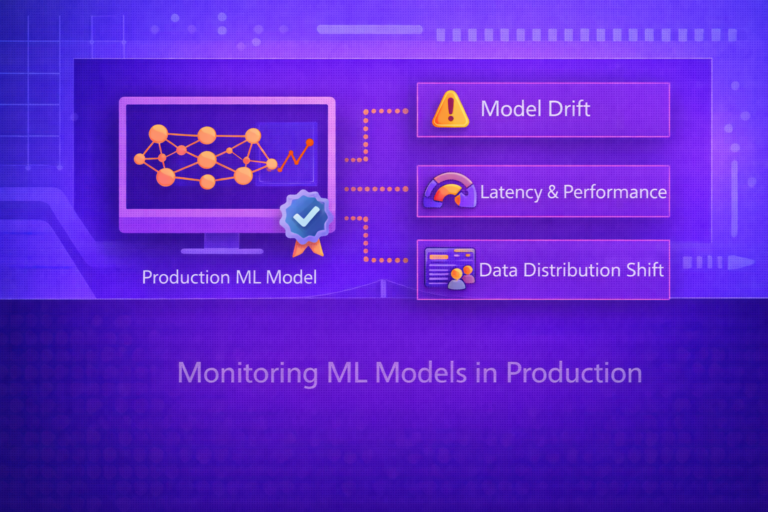
24. Online Monitoring After Deployment
CI/CD for ML does not end when deployment succeeds. Production monitoring must track:
- request latency
- error rates
- resource utilization
- input schema drift
- feature distribution drift
- prediction drift
- eventual label-based performance degradation
If training distribution is Ptrain(x) and production input distribution is
Pprod(x), then input drift corresponds broadly to:
Ptrain(x) ≠ Pprod(x).
25. Rollback Strategy
Reliable ML CD requires rapid rollback. If production model version is
Mt and the previous stable model is
Mt-1, rollback means:
Mprod := Mt-1.
For rollback to work, the pipeline must preserve:
- old model artifacts
- compatible feature logic
- runtime image versions
- deployment manifests
26. Infrastructure as Code and Declarative Delivery
CI/CD for ML becomes more reliable when serving infrastructure is managed declaratively. Deployment specifications for containers, endpoints, autoscaling, or scheduled retraining jobs should be version-controlled and promoted through the same governance process as application artifacts.
27. Security in ML CI/CD
ML CI/CD pipelines must also address supply-chain and runtime security, including:
- dependency scanning
- container image scanning
- secret management
- artifact integrity
- access controls for model promotion
- audit logs for who changed what and when
28. Testing Categories in ML CI/CD
A mature pipeline may include:
- unit tests: code-level correctness
- integration tests: pipeline stage interoperability
- data tests: schema and quality rules
- training smoke tests: reduced end-to-end execution
- evaluation tests: metric threshold validation
- serving tests: inference endpoint contract validation
- load tests: performance and scalability checks
29. Common Failure Modes
- model promoted without correct data lineage
- training-serving skew due to feature mismatch
- CI passing while model quality silently degrades
- drift not triggering retraining soon enough
- rollback failing because old image or model artifact was not preserved
- data schema changes breaking inference after deployment
30. Strengths of CI/CD for ML
- faster and safer release cycles
- better reproducibility and auditability
- reduced manual deployment risk
- clear promotion and rollback workflows
- better alignment between experimentation and production operations
31. Limitations and Trade-Offs
- training can be too expensive for every code change
- quality validation is more complex than pass/fail software tests
- offline metrics may not predict online business performance perfectly
- data drift can invalidate assumptions even after successful deployment
- full automation may be risky in high-stakes settings
32. Best Practices
- Separate CI checks for code integrity from model-quality promotion gates.
- Track code, data, features, model, and environment lineage together.
- Use smoke training in CI and full training in controlled Continuous Training pipelines when needed.
- Require statistical validation against baselines before promotion.
- Use canary or shadow deployment for high-risk model changes.
- Preserve rollback-ready artifacts at every stage.
- Monitor production drift continuously after release.
33. Conclusion
CI/CD for ML models extends software delivery into a domain where artifacts are statistical, data-dependent, and vulnerable to environmental drift. This means that release automation must validate not only code correctness, but also data integrity, feature consistency, model quality, deployment safety, and post-release performance.
A mature ML CI/CD system is therefore not just a pipeline runner. It is a controlled lifecycle architecture that links source control, experiment tracking, model registry workflows, containerized deployment, evaluation gates, and monitoring feedback loops. Understanding CI/CD for ML models is essential for building machine learning systems that are not only deployable, but dependable, governable, and sustainable in production.