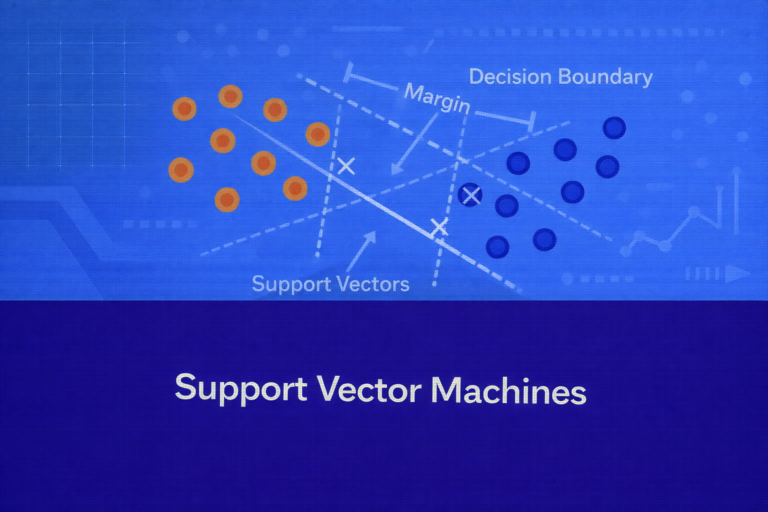
Naive Bayes Classifier
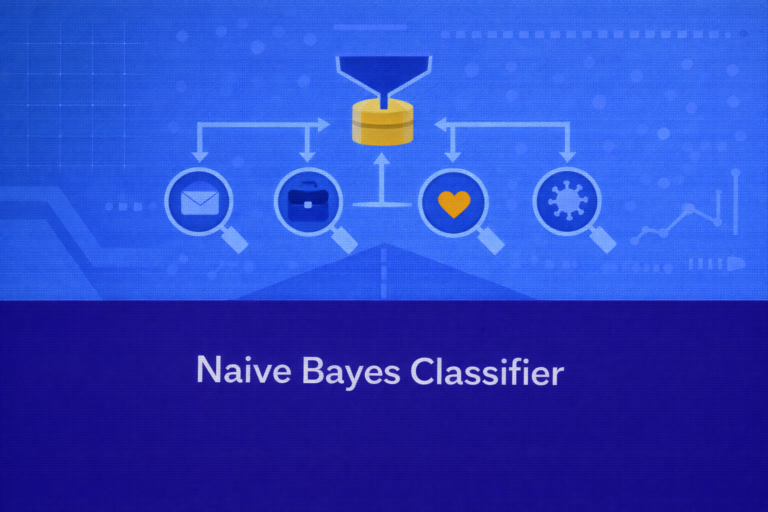
Naive Bayes is a family of probabilistic classifiers based on Bayes’ theorem and a strong conditional independence assumption among features. Despite the simplicity of that assumption, Naive Bayes remains one of the most effective, computationally efficient, and interpretable baseline classifiers…